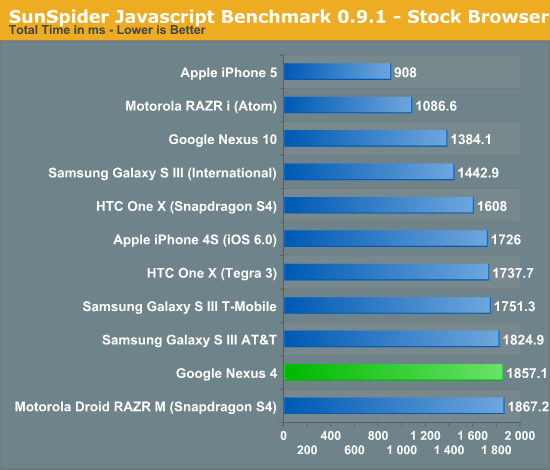
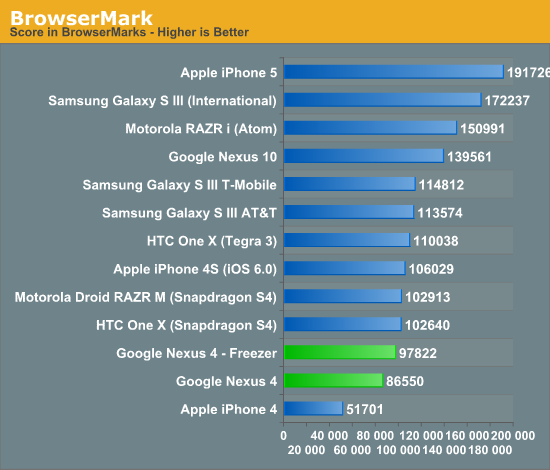
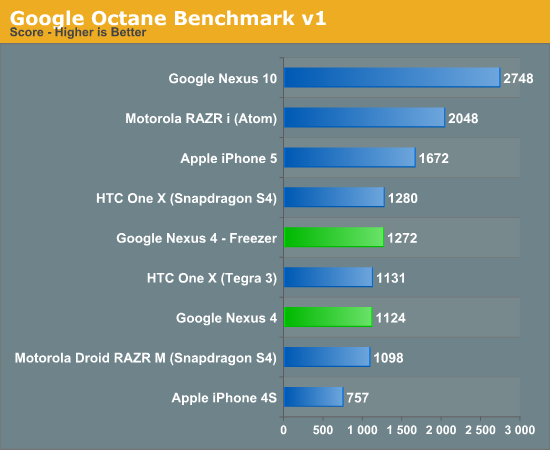
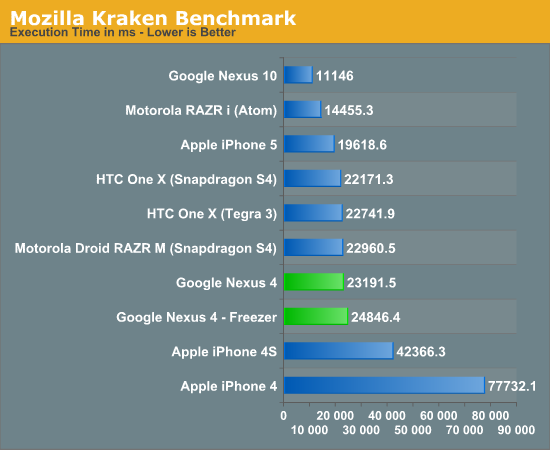
Frågan är om intel kan ha samma låga tdp på sin nya atom processor som på den gamla enkel kärniga, återstår att se.
Intel är grymma på cache design, lång erfarenhet. Dock så tror jag inte de är 10 år före... för 10 år sen så var det Pentium 4 och Pentium M tiden, med cache:s designade i 130nm storleken. Har svårt och tro att de fortfarande hade bättre latency än moderna ARM processorer.
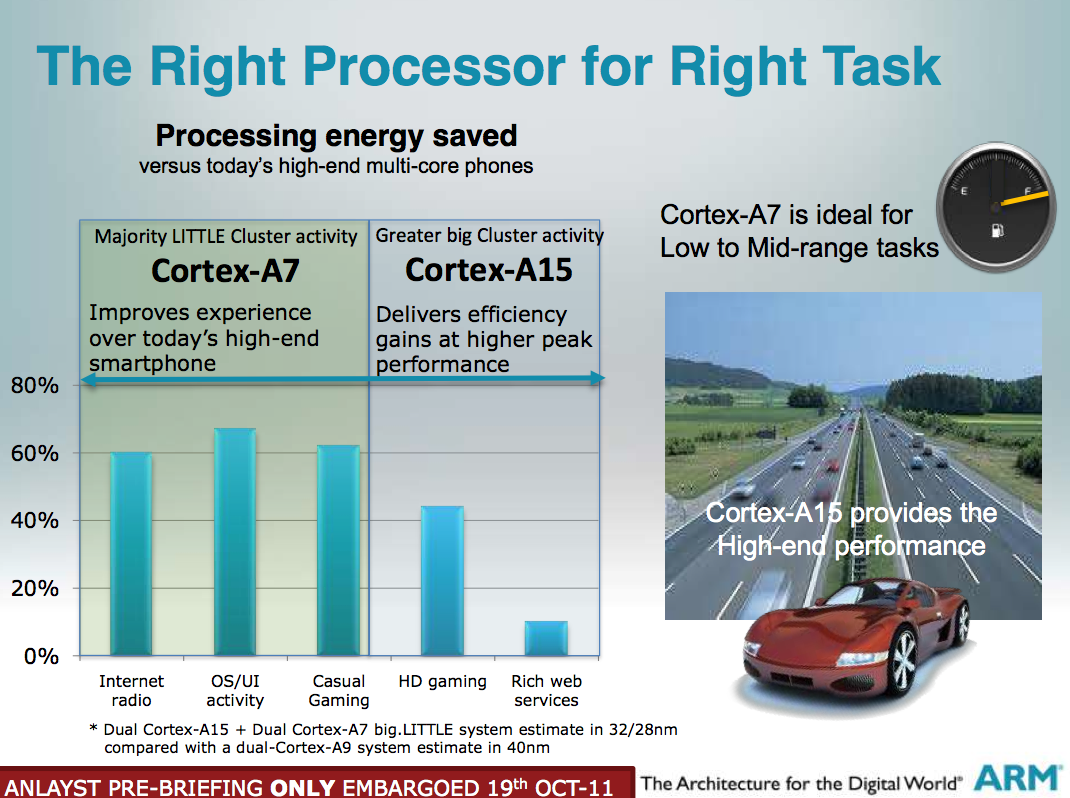
Också lite synd att inte senaste S4:an inte var med i alla stapel diagram (så man kunde se förbättringen mellan ARM generationerna).
Nya Qualcomm 600 processorn verkar ju krossa i prestanda jämfört tillockmed ifrån den väldigt snarliga S4 Pro. Så ett nytt uppdaterat test med alla moderna plattformar hade jag gärna sett innan jag dragit några slutsatser.
Just Multi-threading efficiency är ju "native kod" = teoretisk performance (iaf android räknat), och som de skriver för intel SoC:en så är det ju till stor del för att du kör 2 trådar på processor kärna (därmed delad cache på båda trådarna såklart) samt deras väldigt grymma cache design överlag.
Tittar man på Java JVM virtualisation performance som faktiskt är den faktiska prestandan du får ut av en android telefon så ser det väldigt annorlunda ut,
"Java code is Atom's achille's heel: integer performance is 40% slower than its direct competitor (S3/MSM8660) - this is the kind of code apps use for the most part. Floating-point (FP32) does much better - thanks to the relatively more powerful FPU x86 brings."
Dock så är ju testet ganska utdaterat, är säker på att senare version av dalvik ökar intel prestandan markant under JVM.
Nu skall ju inte nya intel processorn tävla emot s4 Pro längre, utan det är ju Snapdraon 600, 800 och så småningom Exonys Octa..
Vi får hoppas Anand Tech (eller någon annan) gör ett test på alla moderna SoC's under en senaste Dalvik, endast då kan vi faktiskt se hur prestandan ser ut mellan de olika arkitekturerna.
Jag tror nya clovertrail ligger närmre s4 pro än den 600/800/Octa... men kommer bli intressant och se (nån lär ju göra ett uppdaterat test snart)
Utöver prestanda, prestanda/effekt så har ju x86 på Android en stor nackdel, och det är ju att trots att man skall köra emot JVM så finns det fortfarande en hel del apps som kallar native arm libraries vilket resulterar i -> "not supported by your device" fel för intel SoC:arna.. det är ju lite tråkigt
Ok, hade fel. ARM är mer än 10 år efter Intel i L2 cache design. För 10 år sedan hade Intel Pentium M och P4 som hade L2 caches med latenser kring 20-30 cykler (idag är det runt 10 cykler) medan ARM har runt 40 cykler till L2. Rätt kommentera skulle vara att AMD ligger runt 10 år efter i L2 cache design (Piledriver har en 2M cache på ~20 cykler latens, vilket matchar Pentium M rätt bra), och AMD i sin tur ligger långt före ARM.
Sedan tror jag inte TDP blir ett problem för dual-core Atom då Clover Trail (dual core Atom) har en TDP på <2W (många hävdar 1.7W) vilket är betydligt lägre än många ARM SoCer som ligger runt 4W TDP.
Det test jag länkade till refererar till Android 2.3. Håller på att skapa en Dalvik benchmark baserad på de Java program som finns på denna site men kan säga redan nu att Davik prestanda verkar ha förbättrats rätt rejält för x86 till Android 4.0. Kommer släppa denna benchmark gratis när den är klar.
Vad det gäller NDK applikationer så har Intel skapat en infrastruktur som automatiskt konverterar ARM-maskinkod till x86-maskinkod. Detta sker helt automatiskt i "molnet", har laddat ner en hel del spel till min Medfield telefon (och många av dessa använder NDK) och än så länge har precis var enda spel fungerat. Så det blir inga "not supported by your device" fel, du får gärna peka på något program som jag ska testa.
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer