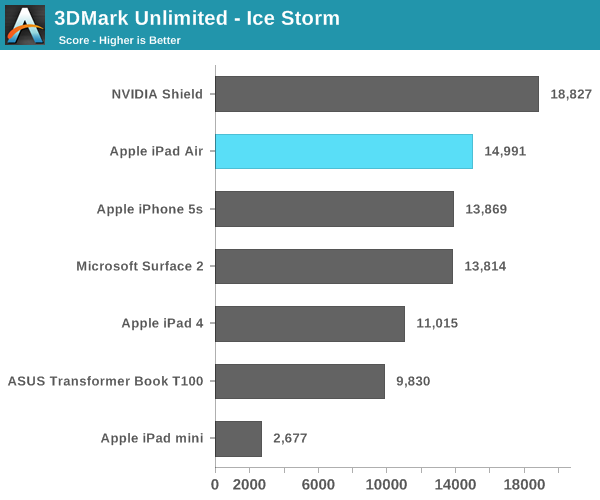
Tycker det är väldigt orättvist mot nVidia. Tyvärr är ju de benchmarks som idag används för mobila plattformar helt bedrövliga om man vill veta hur en viss enhet står sig mot en annan i "verkliga" program, iPad4 vs iPad Air (A6 mot A7) är nog en av de mesta talande exemplen: benchmarks som Geekbench pekar på att A7 är x3 snabbare men i verkliga program har det visat sig att A7 presterar runt 30-40% bättre än A6...
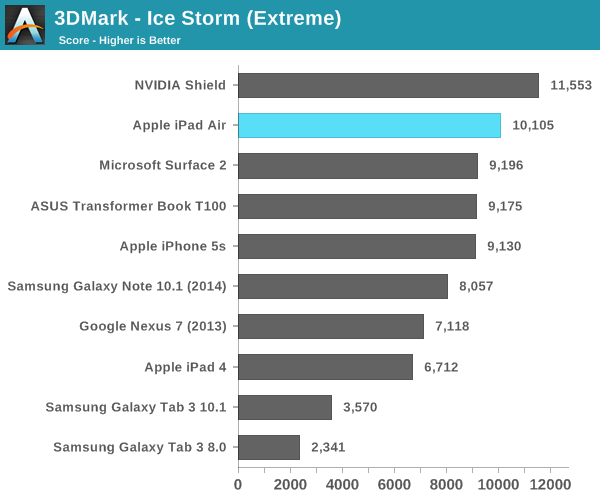
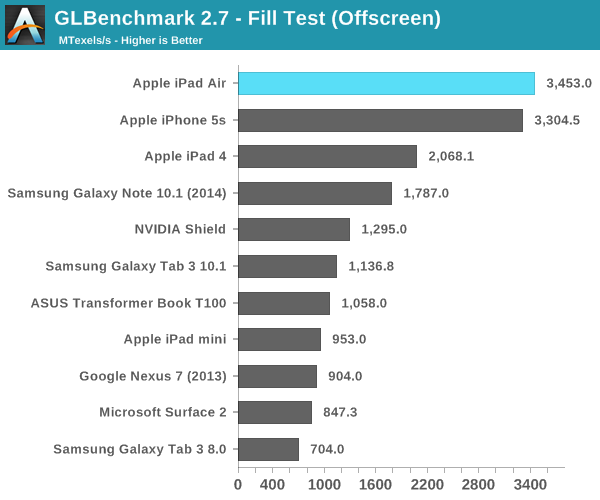
Samma problem tycker jag det finns med de grafikbaserade benchmarksen, PowerVR presterar brutalt bra i alla de benchmarks som mäter rå triangel kapacitet, rå fill-rate kapacitet etc. Men när det kommer till saker som mer liknar vad ett spel skulle skapa för arbetslast, t.ex. 3DMark (som fortfarande inte är i närheten ett lika bra test som ett "riktigt" spel) så presterar ju både Z3770 och Snapdragon 800 i nivå med A7 och Tegra 4 är ju det SoC som presterar bäst (även om det är med liten marginal)!
Tycker det är så skönt att se att nVidia äntligen skippar idiotin med många och relativt långsamma CPU-kärnor när de designar Denver. Varför göra 4 (eller 8) kärnor med 32kB L1 cache och relativt "smal" design när samma mängd transistorer kan ge 2 kärnor med 128kB/64kB L1 och en väldigt "bred" design (betydligt bredare än vad AnandTech gissar att A7 är).
Gissar att "7-way superscalar" inte betyder att den kan avkoda 7 instruktioner per cykel (då lär den får en rätt hög TDP alt. väldigt låg frekvens) utan att den kan köra upp till 7 instruktioner per cykel. Det kan jämföras mot "big-core" x86 där Sandy/Ivy Bridge kan köra 6 µops och Haswell 8µops!
Tror däremot inte att Denver kommer få speciellt mycket högre IPC än Apples A7, effekten av att öka bredden på en CPU avtar extremt snabbt med varje steg. Att gå från 1->2 ger 50-90%, 2->4 ger kanske 30-40%, 4->8 kanske ger 10-20% (jämför IPC skillnaden mellan IVB och HSW som gick från 6->8). Sedan har det visat sig att Apple lade extremt mycket krut på en väldigt bra L1 och L2 cache i A7, frågan är om nVidia lyckas lika bra här då det är extremt svårt att designa ett bra minnesaccess-system i en modern CPU. Att Silvermont (som är 2-way superscalar) står sig så väl är p.g.a. att den har den bästa L2-cache designen av alla nu existerande mobil CPUer, Apples A7 inräknad.