Skrivet av Xinpei:
Njae. Intels 10nm är ganska snarlik i storlek till TSCMs och GlobalFound 7nm. Båda är inte heller riktigt 10nm utan är mest försäljningsknep.
Beror nog på båda faktorerna faktiskt. AMD har nästan slagit i guld i och med deras helix-arkitektur i form av CCX cluster som gör att yielden ökar kraftigt. Vilket gör att man får ut fler kretsar per wafer men även kan använda de mindre perfekta sådana genom att enbart avaktivera cluster och därigenom lansera defekta kretsar som produkter i lägre segment. Detta betyder i sin tur att de kostar mindre att skapa. Intel kör ju samma gamla tillverkningssätt (den mer traditionella typen av CPU:er) utan cluster och därför kan man inte få i närheten av samma Yield som AMD och därför kostar de mer också.
Detta är självfallet en väldigt överskådlig skillnad och för mer djupdykande så kan säkert andra komma med mer djupgående instick i ämnet eftersom jag inte är den mest pålästa personen inom kretstillverkning.
Min poäng är dock att eftersom AMD kör med sin Ryzen-lösning så är deras CPU:er lite mindre komplicerade och det kan självfallet göra att deras tillverkningsteknik är mindre komplex än Intels och framförallt.. Yielden är betydligt bättre.
Sedan har ju självfallet Intel fullständigt legat på latsidan och tagits på sängen när det kommer till AMDs framgång med Ryzen. Framförallt när det kommer till pris/prestanda samt t.ex. SMT eller överklockning på i stort sett hela segmenten.
AMD släpper ju sin "7nm" Zen 2 i början av nästa år.
Det överstämmer inte alls med Sweclockers sammanställning som snarare pekar på 10-20% som max.
Mycket pekar på det ja. Det ligger även i Intels intresse att förneka detta eftersom det vore ett enormt bakslag rent prestigemässigt för Intel. En sak är dock säker... Den "10nm" som det snackas om nu är inte samma som den "10nm" som skulle lanseras någonstans mellan 2015 och 2016.
Det som skrivs ovan har skrivits massvis med gånger på alla möjliga forum. Enda som är lite märkligt är att de nyckeltal och fakta som finns inte riktigt går i takt med den beskrivningen.
Påstående: "AMD har nästan slagit i guld i och med deras helix-arkitektur i form av CCX cluster som gör att yielden ökar kraftigt."
Om det vore sant borde vi se att AMD bruttomarginal öka kraftigt, framförallt då man sagt i sina möten med investerare att genomsnittligt försäljningspris har klart ökat sedan lansering av Zen. Bruttomarginal=Bruttovinst/Försäljning där bruttovinst är försäljning minus direkta kostnader för tillverkning (d.v.s. exklusive saker som FoU, administration och liknande).
Ändå har Intel ~50 % högre bruttomarginal jämfört med AMDs senaste rapport (~60 % vs ~40 %).
Påstående: "Vilket gör att man får ut fler kretsar per wafer"
Zen är 210 mm² på GF 14 nm, CFL-R är 178 mm² (enligt der8auer, mätte själv på uppskalad die-shot och fick det till 175 mm² så har fullt förtroende på der8auer siffra) på Intels 14 nm. Det inkluderar en iGPU på 40-45 mm².
Påstående: "Intel kör ju samma gamla tillverkningssätt (den mer traditionella typen av CPU:er) utan cluster och därför kan man inte få i närheten av samma Yield som AMD och därför kostar de mer också."
???
En av de stora fördelarna med en ring-buss är att man kan skala en sådan design på betydligt fler sätt än CCX och mesh-varianten. Upplösningen i en ring-buss är logiskt sett en kärna, men av placeringsskäl blir upplösningen två kärnor.
Upplösningen för en mesh blir av placeringsskäl steg i form av NxM då kretsen är rektangulär. Man har 4x4 (LCC), 4x5 (HCC) samt 6x6 (XCC) där man dedicerat översta raden till I/O samt två "rutor" tas upp av minneskontroller.
Upplösningen med CCX är 4C. Att man valt just 4C är med stor sannolikhet dikterat av att man använder sig av en cross-bar mellan kärnor och L3$. Fördelen med x-bar är att latensen är konstant mellan alla punkter, nackdelen är att antalet transistorer växer exponentiellt med antal anslutningspunkter.
Ett uppenbart misstag Intel gjorde från Nehalem fram till Broadwell var att dela all för mycket av designen mellan konsument och server. Det är olika saker som är viktiga för prestanda i konsumentlaster (latens > bandbredd) jämfört med server-laster. Vidare har server/datacenter kretsar helt andra krav på I/O-jämfört med konsumentprodukter.
Av Zens 210 mm² är det en hyfsad andel transistorer som egentligen bara är relevanta för server, bl.a. just I/O samt logik för multi-kretslösningar. Finns rätt många rykten som pekar på att för Zen2 kommer det finnas i alla fall en krets som blir exklusiv för server, något som känns väldigt vettigt!
I Intels fall var det största problemet att en ring-buss på serversidan att latensen ökar linjärt med antal CPU-kärnor samt att bandbredden skalar som logaritmen ur antal anslutningspunkter. Fördelarna är väldigt låg latens vid få anslutningar då det går att klocka en ring-buss väldigt högt, antal transistorer för ring-bussen växer bara linjärt med antalet anslutningar. Nackdelen är att det inte skalar speciellt långt, redan vid 8C ser man definitivt tecken på begynnande flaskhalsar.
Ovanpå det är en optimal cache-design för desktop inte alls samma som en optimal cache-design för server. Något vi fått väldigt många exempel på när SKL-S ställs mot SKL-X i typiska konsument-program. Det är samma beräkningsenheter i alla Skylake, men de har väldigt olika cache-design.
Få krets må spara FoU kostnad i form färre litografimaskar (dessa börjar bli rejält dyra). Kostnaden att ta fram varje kretsdesign är en engångskostnad, säljer man tillräckligt många enheter av en viss krets är det mer optimalt att designa flera kretsar då man får ut fler enheter per wafer p.g.a. bättre bruttomarginaler på produkterna (dubbel area ger mindre än hälften så många kretsar då wafer är rund och kretsarna rektangulära).
Påstående: "Det överstämmer inte alls med Sweclockers sammanställning som snarare pekar på 10-20% som max."
Då mitt påstående om >50 % högre prestanda för Intel refererade enbart till fall där SIMD är primär flaskhals (Matlab, Octave, NumPy, machine-learning, m.fl.) så finns noll tester för detta i SweC test. Detta är ett exempel där ring-bussen eller möjligen två-kanals minnesbuss är en flaskhals då det teoretiskt borde vara närmare 100 % fördel, något man också ser hos t.ex. i7-7700K (att RAM nog är flaskhals antyds av att SKL-X presterar väsentligt bättre i dessa fall).
SweC speltester visar på ~20 % högre IPC för Intel vid heltal (30-40 % faktiskt prestanda) och rätt mycket jämt skägg sett till IPC för flyttal.
TechReport hade med några syntetiska tester som där primär flaskhals är AVX-optimerad kod, just dessa är inte matrisberäkningar men allt som kan beskrivas som matriser kan väldigt effektivt hanteras med SIMD -> väldigt generellt för vetenskapliga beräkningar, men inte lika enkelt att använda i typiska desktop-applikationer
Skrivet av wowsers:
Kommer från Brian Krzanich (anandtech, deras källa intressant kring 28:37, citat börjar ungefär 33:55).
Helt lysande svar, ytterst märkligt att inte fler uppskattar detta inlägg.
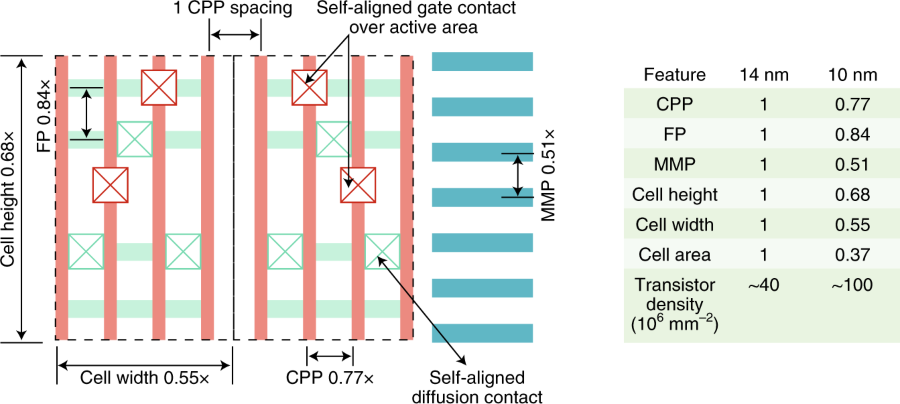
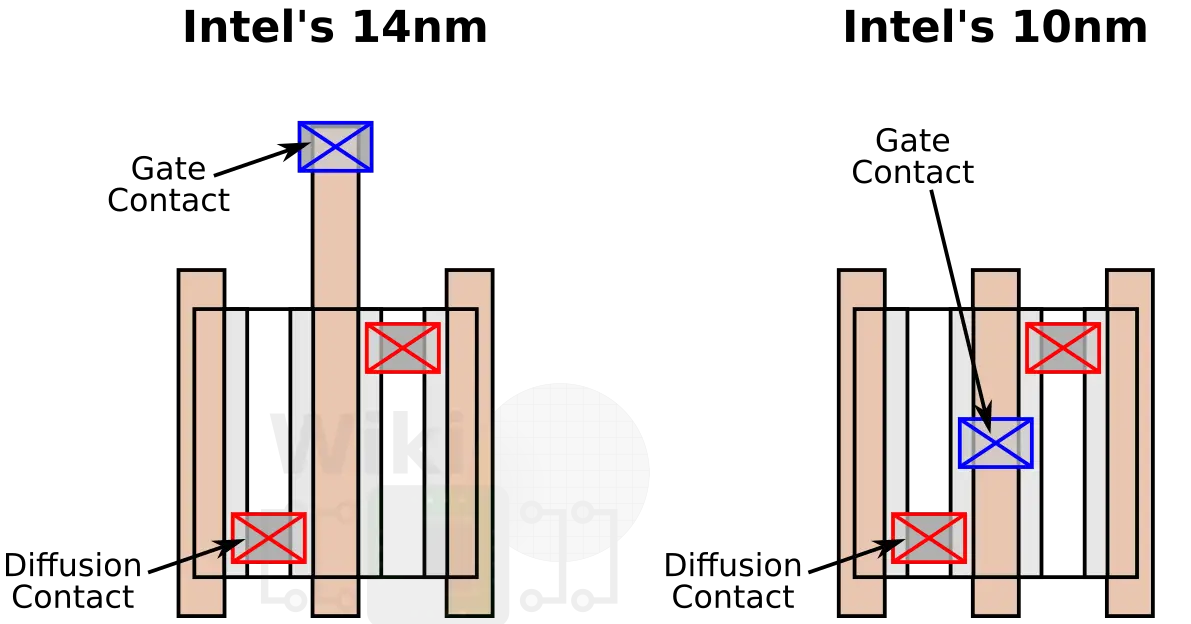
Går ju inte avgöra hur stor andel av kretsen som kväver mer än quad-pattern. Utan att ha några som helst djupkunskaper kring kretstillverkning känns detta som en släng av hybris från Intels sidan. Enligt presentationen från dem själva klarade man sig med double pattern i 14 nm.
När man vet att fler litografisteg både är dyrt (fler vändor genom maskinerna minskar kapaciteten) och ökar risken för fel i kretsarna (så minskar utbytet) verkar det dumdristigt att i ett steg gå från SADP till >=SAQP. Kanske inte allt för vågad gissning då att en sak man ändrat i "nya" 10 nm är att i alla fall inte gå över quad-pattern (för det behövs även om man ändrar MMP, TSMC använder också SAQP för vissa delar i sin 7 nm).
Samsung siktade precis som Intel initialt på en MMP på 36 nm på sin 7 nm. Det var dock villkorat på att man fick igång EUV. När EUV drog ut på tiden (har vi hör att EUV blir försenat förut...) skapade man ju sin intermediära "8 nm" nod som är en förbättrad 10 nm variant (precis som deras 11 nm är en förbättrad 14 nm).
Tror det är rätt garanterat att Intel har kapat finesser från sin ursprungliga 10 nm design. När/om de lyckas rulla ut den "nya" 10 nm lär vi kanske få bättre insikt i vad som ändrats.