

Senast redigerat
Intels arkitektur "Ice Lake" på 10 nanometer hittar ut på Geekbench

Skrivet av Dual-Tjur:
min i3 8350k har mest L3 cache/tråd (+9700k). Är min processor bra och resten vingklippta då??????
Tabellen som sådan har ingenting att göra med hur specifika modeller presterar mot en annan, utan hur mycket cacheminne Intel ger respektive arkitektur. Sedan stängs funktioner av för att segmentera och skapa mer prisvärda modeller än något fullfjädrat.
Din Core i3-8350K baseras på en krets med stöd för Hyperthreading, men det är avstängt för att du skulle kunna köpa en Core i3-8350K till det priset. Finns säkert även Core i3-8350K som i grunden är sexkärniga med 12 MB L3-cacheminne, men som Intel skurit ned för att skapa just en Core i3-8350K. Likaså är Core i7-9700K baserad på en krets med åtta kärnor, men där Hyperthreading och 1/4 av allt L3-cacheminne är avstängt (9 MB istället för 12 MB). Det ändrar inte hur förhållandena i cacheminne ser ut för den arkitekturen i grundutförande.
Skrivet av houze:
Skylake-X har väl som minst 1,375MB/core, finns vissa Skylake-X som har betydligt mer, t.ex. Platinum 8156 som har 4.125MB/core och några av de uppdaterade HEDT-varianterna som kommer i vinter kommer ha lite mera L3.
Alla kretsar med Skylake-X har 1,375 MB L3-cacheminne per kärna. I de fall där det finns mer är det nedskurna kretsar, där Intel valt att stryka ett antal kärnor men behålla respektive kärnas delade L3-cacheminne.
Skrivet av Paddanx:
@Jacob en lite fråga... har ni någon förklaring varför Intel valt att göra denna ändring?
När man gick från Core2Duo/Quad var det ju väldans prat om att man gick just från stor L2 till mindre L2 och skulle ha L3.
https://ark.intel.com/products/35428/Intel-Core-2-Quad-Proces...-
Tex värsting Quad, hade ju hela 12MB L2 cache, att jämföra med dagens 6-8MB L3 och så 256kB per kärna L2.
Är det så att man anser att L2 behovet ökat igen? För jag vill minnas förklaringen till detta var för att med mindre L2 kunde man få ner latensen på L2 cachen. Då borde man ju få sämre L2/L1 prestanda nu, men mer av det?
(Ser man på tex Skylake-X vs Skylake tester ser man ju också att i vissa ändamål har de sämre prestanda)
I dagsläget är väldigt lite känt om Ice Lake, så jag har ingen förklaring på det. Skulle tro att @Yoshman kan göra en kvalificerad gissning om vad ett dubblerat L2-cacheminne kan tänkas ge sett till hur Intels arkitekturer ser ut idag.
Ett större minne bör dock som du skriver ge högre latens och i vissa laster ge sämre prestanda, men det är ju möjligt att Intel kompenserar det bortfallet med andra förbättringar i arkitekturen. Att de ändå ökat mängden cacheminne talar ju för att Intel ser fördelar med att göra det.
Visa signatur
Citera flera
Citera
(4)

Shit vad glömsk jag är, men vad hette 5XXX-serien som släpptes på våren strax innan Skylake? Hade inte den massor med cache?
Visa signatur
System: CPU: AMD Ryzen 9 3900X, MB: Gigabyte X570 Aorus Elite, Minne: Corsair 32GB DDR4 3200MHz, GPU: Asus GeForce RTX 2080 Super ROG Strix Gaming OC
Citera flera
Citera

Skrivet av FredrikMH:
Shit vad glömsk jag är, men vad hette 5XXX-serien som släpptes på våren strax innan Skylake? Hade inte den massor med cache?
Menar du broadwell med grafiklösningen?
Visa signatur
The cookie goes *crumble*.
Citera flera
Citera

Skrivet av FredrikMH:
Shit vad glömsk jag är, men vad hette 5XXX-serien som släpptes på våren strax innan Skylake? Hade inte den massor med cache?
Du tänker på 5775c och 5765c Broadwell, som var samma cache som dessa ovan, men de hade ett L4/sDRAM på 128MB också, vilket med tex DX11 får CPUn att få satans jämn och bra prestanda, trots ynka 1600Mhz RAM stöd och stock frekvens på 3,5Ghz
Är en underbar CPU btw i 4-4.2Ghz med den cachen
Citera flera
Citera
(1)
Skrivet av roxkz:
Menar du broadwell med grafiklösningen?
Skrivet av Paddanx:
Du tänker på 5775c och 5765c Broadwell, som var samma cache som dessa ovan, men de hade ett L4/SDRAM på 128MB också, vilket med tex DX11 får CPUn att få satans jämn och bra prestanda, trots ynka 1600Mhz RAM stöd
Är en underbar CPU btw
Jaaaa, nu vaknade en del hjärnceller som låst in sig i arkivet.
Visa signatur
System: CPU: AMD Ryzen 9 3900X, MB: Gigabyte X570 Aorus Elite, Minne: Corsair 32GB DDR4 3200MHz, GPU: Asus GeForce RTX 2080 Super ROG Strix Gaming OC
Citera flera
Citera
Skrivet av FredrikMH:
Jaaaa, nu vaknade en del hjärnceller som låst in sig i arkivet.
Vi säger att informationen låg långt ner i en hårddisk... tog tid för systemet att söka upp informationen
Citera flera
Citera
Det var mycket man lärde sig om specifika arkitektur.
Här är geekbench på cannon-lakes
Både single och multicore motsvarar denna i artikeln (4150/7950)
dock är base 2.2 max 3,07 mot base 2.6Ghz
En fråga till då man troligen visste lite om arkitektur/modeller.
Är mobilprocessorer/desktop processorer skapade från samma krets/arkitektur???
Som man ser från artikeln handlar det om en "mobilarkitektur" (so-dimms)
Senast redigerat
Citera flera
Citera
Skrivet av Dual-Tjur:
och min i3-8350k utsågs från en i5 också. Så är i3=i7 nu ????
Ja du... går du till laptop så har du 2-core i7or, så varför inte?
Skillnaden mellan tex i5 8350u och i7 8550u är typ frekvensen, och 2MB cache.
Och pentium har ju blivit i3... i3 blivit i5.. och i5 blivit i7... och i7 blivit i9, och vi alla som köpt CPUer har blivit blåsta på pengar på ett eller annat sätt för samma mängd cache i nästan 10 år
Citera flera
Citera
Skrivet av Paddanx:
Ja du... går du till laptop så har du 2-core i7or, så varför inte?
Skillnaden mellan tex i5 8350u och i7 8550u är typ frekvensen, och 2MB cache.
Och pentium har ju blivit i3... i3 blivit i5.. och i5 blivit i7... och i7 blivit i9, och vi alla som köpt CPUer har blivit blåsta på pengar på ett eller annat sätt för samma mängd cache i nästan 10 år
Troligtvis så är inte alla cache/kärnor 100%-tiga eller vissa bättre lämpade för mobilbruk då de tål lägre spänningar???
Samma sak i5-9600K har 1-2 kärnor "skadade"?
---------------------------------------------------------------------------------
CANNONLAKE-ICE LAKE JÄMFÖRELSEN (mobile?)
en tabell som borde ha varit med i artikeln
dessutom så är tabellen i artikeln missvisande som skapade rätt så mycket förvirrning
L3 cache är INTE PER KÄRNA (eller jo den blir det forfarande )
PER KÄRNA
L1 Instruction Cache______ 32.0 KB x 2-----------32.0 KB x 2
L1 Data Cache___________ 32.0 KB x 2-----------48.0 KB x 2
L2 Cache_______________ 256 KB x 2-----------512.0 KB x 2
DELAT AV ALLA KÄRNOR
L3 Cache_______________ 4.00 MB x 1----------4.00 MB x 1
Så dubblering av L2 och 50% större L1 Data Cache. Man blir inte klokare dessa tider. Tur att man har Yoshman
Så vad jag har lärt mig från denna tråd är att min i3-8350k är troligtvis en 7700K som har fyra kärnor och 100% L3 cache på. Dock utan HT
Senast redigerat
Citera flera
Citera
Skrivet av Dual-Tjur:
Troligtvis så är inte alla cache/kärnor 100%-tiga eller vissa bättre lämpade för mobilbruk då de tål lägre spänningar???
Samma sak i5-9600K har 1-2 kärnor "skadade"?
Hmm, hade för mig 9600 var 8600 re-branded.
Citera flera
Citera
tror att der8bauer mätte båda delidade 9900k och 9600k och längden på dem var detsamma. (kan någon bekräfta det)
och jag trodde det motsatta om min 8350k
Så vad jag har lärt mig från denna tråd är att min i3-8350k är troligtvis en 7700K som har fyra kärnor och 100% L3 cache på. Dock utan HT
Eller är det en vingklippt 8700k?
Så nu vet jag att jag ska ha en 8600k och inte 9600k
Senast redigerat
Citera flera
Citera

Skrivet av Paddanx:
@Jacob en lite fråga... har ni någon förklaring varför Intel valt att göra denna ändring?
När man gick från Core2Duo/Quad var det ju väldans prat om att man gick just från stor L2 till mindre L2 och skulle ha L3.
https://ark.intel.com/products/35428/Intel-Core-2-Quad-Proces...-
Tex värsting Quad, hade ju hela 12MB L2 cache, att jämföra med dagens 6-8MB L3 och så 256kB per kärna L2.
Är det så att man anser att L2 behovet ökat igen? För jag vill minnas förklaringen till detta var för att med mindre L2 kunde man få ner latensen på L2 cachen. Då borde man ju få sämre L2/L1 prestanda nu, men mer av det?
(Ser man på tex Skylake-X vs Skylake tester ser man ju också att i vissa ändamål har de sämre prestanda)
Att Intel gick från stor L2 till liten L2 + L3 berodde primärt på att de ville ha ner latency till L2. Den gick från 14 cykler ner till 10, vilket Intel tyckte var värt att den blev mindre (och de simulerade säkert saken ordentligt). Dessutom var det bra att det blev mindre snoop-trafik till varje kärnad L2, eftersom en inklusiv L3 kunde hantera detta.
Om du läser detaljerna om nyare processorer, ser du att latencyn krupit upp igen, och är (om jag minns rätt) uppe på 12 cykler igen. Detta kan bero på att Intel sparar energi i L2, men också på att designen nu är mer förlåtande iom att Skylake-X kan ha en mycket större L2. Skall man ändå ha en 12-cykels latency, kan man ju utnyttja att den kan bli lite större.
Sen finns det en allmän trend att alla cachar växer just nu. Zen har vi ju i artikeln, och Apples cache har vuxit för varje generation det senaste. I A12 är det ensligt Anandtech 128KB i både L1D och L1I. Uppenbarligen finns det prestanda att tjäna och energi att spara där.
Skickades från m.sweclockers.com
Visa signatur
5900X | 6700XT
Citera flera
Citera

Hoppas att dom kommer med Ice Lake snart och den blir bra!
Intel har varit skittråkigt, allt dom lanserat det senaste halva decenniet har varit skittråkigt.
Citera flera
Citera
(1)

Verkar som kretsen i fråga saknar turbo, ST vs MT resultaten har mer eller mindre exakt samma kvot som i3:modeller som saknar turbo.
Frågan är vilken frekvens kretsen går på, om det verkligen är 2,6 GHz har man gjort en rätt rejäl ökning av heltals IPC!
Skrivet av Dual-Tjur:
@jacob. kan vi få me en vanlig caffe i jämförelsen? Här t.ex min i3
Varför inte jämföra med processorer som är liknande från nuvarande familj.
https://i.imgur.com/M9hPyg2.jpg
i3 har 2MB i5 har 1,5MB och i7 har 2MB l3 cache minne per kärna.
År inte denna en processor fråm 10nm som är redan ute och som @yoshman har försökt att köpa?
Enda 10 nm som finns är väl i3-8121U? Knappast något jag skulle vilka lägga pengar på... Den jag (fortfarande) väntar på är i7-8559U (samma CPU som sitter i dyrast 13" MBP), tydligen inte ensam för NUC:en med den CPUn ligger nu högst på prisjakts lista över "barebones". SweC skrev om denna NUC i somras och den lanserades i USA i augusti, är nu första veckan i november
Skrivet av mpat:
Sen finns det en allmän trend att alla cachar växer just nu. Zen har vi ju i artikeln, och Apples cache har vuxit för varje generation det senaste. I A12 är det ensligt Anandtech 128KB i både L1D och L1I. Uppenbarligen finns det prestanda att tjäna och energi att spara där.
Och där har vi ännu en i raden av saker där 64-bitars ARM slår x86 på fingrarna...
Varför ser vi inte större L1D$ på x86, den har varit samma 32 kB i evigheter...
Svaret är latens, page-storlek, TLB samt virtuella vs fysiska adresser.
När man valde 4 kB som normal page-storlek i mitten av 80-talet var det helt rätt. Faktum är att alla utom Alpha (tror de hade 8 kB men den kom ju senare) valde just 4 kB, inklusive 32-bitars ARM.
Varje virtuella adress matchar exakt en "page", en "page" innehåller information kring var den fysiska lagringen håller hus (kan vara i RAM eller swappat, från nu förutsätter vi att den är i RAM).
4 kB betyder att de tolv minst signifikanta bitarna i adressen är densamma oavsett om man refererar till den virtuella adressen eller den fysiska adressen i RAM.
32 kB / 4 kB -> 8. Är ingen slump att det är L1D$ är uppdelad i 8 delar (cachen är 8-set associativ). Varje del blir då just 4 kB stor, vilket betyder att man kan ha en fysiskt indexerad L1D$ men man kan ändå slå upp L1D$ parallellt med TLB (Translation Lookaside Buffer, cache för virtuell till fysisk adress översättning).
Finns en rad orsaker varför man inte vill tagga cache med virtuella adresser, så att kunna slå upp TLB och L1D$ parallell är kritiskt för att få låg latens.
Varför har man då inte bara fler än 8 delar? För det drar ström! Att gå från 1 till 2 till 4 delar i en cache minskar antalet s.k. "conflict misses", d.v.s. att man måste slänga ut något för att data måste läggas på samma plats. Alla cache-lines i varje del har ett index som beräknas från den låga adressbitarna, d.v.s. en viss adress har en fixerad plats i varje del (i varje cache-set).
Efter 4-set associativ cache ser man normalt väldigt liten minskning av "conflict misses", men man måste slå upp i alla delar parallellt men bara en kan någonsin ge en träff. Så ju fler delar, ju mer ström kostar en uppslagning
Lär ju vara så att Intel tycker vinsten att ha större L1D$ är värd att gå till 12-set associativ L1D$.
Vad har det med ARM64 att göra? Hur lyckades Apple med hela 128 kB, både för L1D$ och L1I$? Jo, ARM64 tillåter standardstorleken på en "page" att vara 4 kB (legacy skäl säkert), 16 kB samt 64 kB. För desktop skulle nog 64 kB fungera helt OK, men Apple droppade 4 kB stödet och kör med 16 kB.
128 kB / 16 kB -> 8 set associativ cache räcker!
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Citera flera
Citera
(3)
Skrivet av Jacob:
I dagsläget är väldigt lite känt om Ice Lake, så jag har ingen förklaring på det. Skulle tro att @Yoshman kan göra en kvalificerad gissning om vad ett dubblerat L2-cacheminne kan tänkas ge sett till hur Intels arkitekturer ser ut idag.
Ett större minne bör dock som du skriver ge högre latens och i vissa laster ge sämre prestanda, men det är ju möjligt att Intel kompenserar det bortfallet med andra förbättringar i arkitekturen. Att de ändå ökat mängden cacheminne talar ju för att Intel ser fördelar med att göra det.
Det här är förklaringen jag hört kring detta:
Större cache ger högre latens, tyvärr orsakat av att klocksignalen måste vara "tillräckligt" i synk över hela minnesbanken (är ingen expert på de delar så har ingen aning vad "tillräckligt" är). Vid 4-5 GHz hinner inte signalen speciellt långt i en krets!
Här är ändå ett ställe där krympning fortfarande direkt kan hjälpa prestanda. Mindre SRAM betyder mindre avstånd vilket betyder mindre "clock-skew".
Finns en formel (framtagen empiriskt på 70-talet) som beskriver hur en caches miss-rate uppför sig med avseende på storlek

där M0 är miss-rate för ett basfall, C är hur mycket större cache man vill skatta miss-rate för och α är en konstant som beror på applikationen, typiskt 0,3 - 0,7. Tar man värdet 0,5 får man det som folk brukar använda som "mellan-tummen-och-pekfingret-värde", en cache miss-rate minskar ungefär med roten ur storleken.
Grejen är att de flesta desktop-applikationer redan har väldigt hög cache-hit-rate, ofta runt eller över 90 %. En relativt liten minskning av miss-rate kan ändå ge hyfsad effekt på prestanda då det går flera gånger (gånger, inte några tiotals procent) långsammare att hantera en minnesoperation som missar cache.
En gissning blir därför väldigt osäker då det finns så många parametrar som kan variera. 50 % högre L1D$ och 100 % större L2$ med ungefär samma effektiva latens kanske kan ge ett par procent, inte mer. Lär i alla fall vara <10 %.
BTW: att SKL-X och SKL-S presterar så pass olika har inte direkt med latens att göra, inte den latens man normalt hör talas om i alla fall.
Faktum att de har rätt snarlik s.k. load-to-use latens. Det är antal cykler från att man begär något från cache till dess att beräkningsenheterna har data, är nästan alltid den siffran man ser när något säger "latensen på cachen är X cykler".
Här är en mätning (TechReport)

Så vad är förklaringen till att SKL-S presterar bättre jämfört med SKL-X i t.ex. spel, det är ju samma beräkningsenheter och samma teoretiska kapacitet genom front-end och back-end?
SKL-X är optimerad för servers. Där har man typiskt många oberoende saker som körs parallellt. En optimal cache är då en cache där varje kärna har relativt mycket "egen" cache. L3$ är där en s.k. victim-cache, den innehåller bara sådant som trillat ur L2$ så det blir en form av buffert mot RAM.
SKL-S är optimerad för desktop. Det typiska multitrådade programmet här använder flera trådar för att lösa samma problem, d.v.s. relativt vanligt att trådar måste dela data. För att kunna göra detta måste trådarna synkronisera sina läsningar/skrivningar mot delad data, annars blir det pannkaka av det hela (man har en s.k. data-race bug, extremt svåra att hitta!).
Synkronisering kräver nästan alltid (har patent på en form av synkronisering där så inte är fallet) att man skriver till någon delad minnesadress. Här har SKL-S en fördel då dess L3$ är inkluderande av alla L1/L2-cachar. Dels kan man då använda L3$ som ett s.k. snoop-filter, d.v.s. det finns information om vilka kärnor som garanterat INTE har en kopia av data man precis vill skriva. Rent praktiskt finns en bit per kärna, den är satt om kärnan kan ha (falsk positiv är möjlig, men OK) data i lokal cache.
När man väl skriver data hamnar det i lokal L1 för den som skriver samt L3. Detta är INTE fallet för SKL-X (inte heller för Zen som också har exkluderande policy i L3$), där får man bara en lokal kopia men finns ingen delad variant i L3$. Så när någon annan kärna senare vill ta låset eller läsa annan data som någon nyligen skrivet så går det snabbare (har lägre latens) med inkluderande L3$.
Fördelen med exkluderande L3$ policy är att den effektiva storleken ökar, blir summan av L3+lokal cache. Fördelen med inkluderande cache är lägre latens att hantera delad data, är även möjligt att göra prefetch till L3$ där (SKL-X kan då bara göra prefetch till lokal cache, inte till L3$).
Är just därför jag tycker Intel väntande alldeles för länge med att dela upp sin konsument-linje från sin server-linje. Skylake SP blev det nog det största lyftet någonsin mellan två server-generationer, däremot blev nog HEDT lidande för det är inte längre en speciellt bra desktop-krets (finns ett par nischer där det fungerar bra).
Att ring-buss designen börjar krokna vid 8-10 kärnor är knappast något större problem för desktop, framförallt då Windows-desktop börjar krokna redan när man passerar 6 kärnor.
Senast redigerat
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Citera flera
Citera
(3)
Tack som vanligt för dina svar. Man lär sig lite varje gång!
(dock att förstå allt du skriver kräver säkert några kurser uppåt i frågan )
En fråga som jag ställde och jag är fortfarande mycket nyfiken på:
Är mobilprocessorer och desktoprocessorer t.ex Coffe Lake alla samma kretsar??? t.ex 8700K 8350K Pentium sen Nuc och mobilprocessorer från samma familj....är de från en och samma krets?? Där de sen kollar vilka som lämpar sig bäst för specifika modeller? Dvs de stänger av det ena och de andra och stryper stänger av vissa delar för att få "olika modeller"?
-----------------------------------------------------------
Lite andra "undrande diskussioner" som du kan kanske kommentera.
@Jacob Din Core i3-8350K baseras på en krets med stöd för Hyperthreading, men det är avstängt för att du skulle kunna köpa en Core i3-8350K till det priset. Finns säkert även Core i3-8350K som i grunden är sexkärniga med 12 MB L3-cacheminne, men som Intel skurit ned för att skapa just en Core i3-8350K. Likaså är Core i7-9700K baserad på en krets med åtta kärnor, men där Hyperthreading och 1/4 av allt L3-cacheminne är avstängt (9 MB istället för 12 MB). Det ändrar inte hur förhållandena i cacheminne ser ut för den arkitekturen i grundutförande.
@Dual-TJUR: Troligtvist så är inte alla cache/kärnor 100%-tiga eller vissa bättre lämpade för mobilbruk då de tål lägre spänningar??? Samma sak i5-9600K har 1-2 kärnor "skadade"?
@Paddanx: Hmm, hade för mig 9600 var 8600 re-branded.
@Dual-TJUR : tror att der8bauer mätte båda delidade 9900k och 9600k och längden på dem var detsamma. (kan någon bekräfta det?)
@Dual-TJUR : och jag trodde det motsatta om min 8350k. Så vad jag har lärt mig från denna tråd är att min i3-8350k är troligtvis en 7700K som har fyra kärnor och 100% L3 cache på. Dock utan HT på
Senast redigerat
Citera flera
Citera
Skrivet av Dual-Tjur:
Tack som vanligt för dina svar. Man lär sig lite varje gång!
(dock att förstå allt du skriver kräver säkert några kurser uppåt i frågan )
Om just cache-system är Wikipedia helt OK:
https://en.wikipedia.org/wiki/CPU_cache#Address_translation
Den typen av cache som han talar om här kallas för VIPT.
Visa signatur
5900X | 6700XT
Citera flera
Citera
Skrivet av Dual-Tjur:
tror att der8bauer mätte båda delidade 9900k och 9600k och längden på dem var detsamma. (kan någon bekräfta det)
och jag trodde det motsatta om min 8350k
Så vad jag har lärt mig från denna tråd är att min i3-8350k är troligtvis en 7700K som har fyra kärnor och 100% L3 cache på. Dock utan HT
Eller är det en vingklippt 8700k?
Så nu vet jag att jag ska ha en 8600k och inte 9600k
Är en bra fråga. Förr trodde jag 7600k var 8350k, men det kan inte stämma helt pga 8MB Cachen. Så den verkar vara någon mellanväg mellan 7700k och 7600k. Dessa är ju samma processor, men med saker avstängda eller inte.
Skrivet av mpat:
Att Intel gick från stor L2 till liten L2 + L3 berodde primärt på att de ville ha ner latency till L2. Den gick från 14 cykler ner till 10, vilket Intel tyckte var värt att den blev mindre (och de simulerade säkert saken ordentligt). Dessutom var det bra att det blev mindre snoop-trafik till varje kärnad L2, eftersom en inklusiv L3 kunde hantera detta.
Om du läser detaljerna om nyare processorer, ser du att latencyn krupit upp igen, och är (om jag minns rätt) uppe på 12 cykler igen. Detta kan bero på att Intel sparar energi i L2, men också på att designen nu är mer förlåtande iom att Skylake-X kan ha en mycket större L2. Skall man ändå ha en 12-cykels latency, kan man ju utnyttja att den kan bli lite större.
Sen finns det en allmän trend att alla cachar växer just nu. Zen har vi ju i artikeln, och Apples cache har vuxit för varje generation det senaste. I A12 är det ensligt Anandtech 128KB i både L1D och L1I. Uppenbarligen finns det prestanda att tjäna och energi att spara där.
Skickades från m.sweclockers.com
Om du kan hålla samma latens och öka storleken... självklart gör det. Men frågan kommer ju om det var L3 i sig, eller minskningen av L2 som gjorde prestandavinsten. Mao... är 12->14 cykler, när man jämför 3-4Ghz så mycket förlust mot att göra en cache miss pga den var för liten att hålla det man behövde. Skulle tro att där är en fin balans att gå där, och det hänger mer på vad du beräknar, hur bra du kan förutspå data hämtningen (något som spectre/meltdown lär ha skadat en hel del) och hur designen av de omgivande L1 och L3 ser ut.
Jag har mao svårt att tro att en dubblering av L2 inte kommer ha en markant påverkan på både priset på CPUn, samt latensen på data i den. Men om det görs måste ju uppoffringarna som görs vara värda detta. Och som man kan se när man tittar på bara snabbare RAM latens påverkar dagens CPUer så vet jag inte... där kan du tjäna mycket på att få ner 1ns latens i rätt miljö.
Har dock svårt att tro det är energieffektivt... för minne äter ström. Dessa kretsar måste vara igång 100% när kärnan är igång. Och ska du starta upp och stänga av dem från IDLE, måste de antingen vara igång (med data redo), eller stängas av och sedan fyllas igen (vilket också tar resurser). Så det blir väl en fråga om du kan få upp effektiviteten på hela CPUn för att vinna det tillbaka.
Att dagens CPUer tvingas tömma cachen hela tiden pga dessa buggar har kanske ändrat förutsättningen för hur den mer effektiva nivån är?
Skrivet av Dual-Tjur:
Tack som vanligt för dina svar. Man lär sig lite varje gång!
(dock att förstå allt du skriver kräver säkert några kurser uppåt i frågan )
En fråga som jag ställde och jag är fortfarande mycket nyfiken på:
Är mobilprocessorer och desktoprocessorer t.ex Coffe Lake alla samma kretsar??? t.ex 8700K 8350K Pentium sen Nuc och mobilprocessorer från samma familj....är de från en och samma krets?? Där de sen kollar vilka som lämpar sig bäst för specifika modeller? Dvs de stänger av det ena och de andra och stryper stänger av vissa delar för att få "olika modeller"?
Det är ju inte "en" CPU. Utan 2-core är 2-core med eller utan HT, med all cache eller delvis avstängd sådan.
4-core är 4-core, med eller utan HT med full cache eller inte...
6-core är... ja du förstår.
Sen i valideringen blir de ju den CPU de bli. Om de är effektiva i låg spänning, är de perfekta mobila kretsar. Om de klarar högsta frekvenserna blir de top "K" CPUerna. Har de defekt del så kan de stänga av HT och en bit Cache och göra en "i5" eller vad de nu ska kallas. Jag har dock börjat undra om de inte rullar ut mobila separat nu för tiden dock, eftersom deras GPU lösningar skiljer.
Sen är det säkert undantag, där Intel valt att göra något specifikt för att matcha marknaden.
Citera flera
Citera
Skrivet av Paddanx:
Vi säger att informationen låg långt ner i en hårddisk... tog tid för systemet att söka upp informationen
Ja och då ska vi inte prata om den rostiga läsarmen
Visa signatur
System: CPU: AMD Ryzen 9 3900X, MB: Gigabyte X570 Aorus Elite, Minne: Corsair 32GB DDR4 3200MHz, GPU: Asus GeForce RTX 2080 Super ROG Strix Gaming OC
Citera flera
Citera
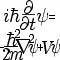
Skrivet av Jacob:
Skylake är Kaby Lake är Coffee Lake är Coffee Lake Refresh (Skylake 4 som jag gillar kalla processorfamiljen). Samma arkitektur, vilket också står skrivet direkt under tabellen.
Fast innan Coffee Lake Refresh har Intel hunnit med Amber Lake samt Whiskey Lake (dock bara för laptops). Så Coffee Lake Refresh är Skylake 6.
Citera flera
Citera
Skrivet av ajp_anton:
Kan någon förklara Intels och AMDs olika strategier kring L1d samt L1i? @Yoshman? =). De verkar ju tänka tvärtom på vilken man ska satsa på.
L1D$
När det kommer till just L1d$ tänker de ju på exakt samma sätt. Både Skylake och Zen har en virtuellt indexerad fysiskt taggad (VIFT) L1D$ där man sett till att index-delen inte har några adressbitar som skiljer sig i den virtuella och fysiska adressen (vilket jag skrev om ovan). Detta är just för att kunna slå upp i L1D$ och TLB parallellt.
Gissningsvis ändras inget här med Ice Lake, mer än att man måste gå från en 8-set associativ L1$ till 12-set associativ för att fortfarande kunna slå upp TLB parallellt. Finns allt få mycket nackdelar med att köra virtuellt indexerad virtuellt taggad (VIVT) för att det ska vara värt det, ARM har testat det för ett gäng år sedan och övergett det (med VIVT försvinner kravet på storlek/associativitet = 4 kB för att kunna slå upp TLB parallellt, men man måste i praktiken flusha cachen mellan varje kontext-switch...).
L1I$
För instruktionscachen har man definitivt tänkt olika. Intel kör samma strategi som för L1D$, d.v.s. VIFT med 8-set associativitet så uppslagen kan gå parallellt med TLB.
AMD kör med 64 kB och 4-set associativ VIFT cache. Varför då?
Att ha en större cache är normalt bättre, framförallt en större L1 då den är så pass liten att ökningar ger procentuellt större utdelning. Är inte heller några problem att hålla latensen på samma 4 cykler vid 64 kB (Apple fixar det även med 128 kB, i alla fall på TSMC 7 nm).
Problemet är att utan andra optimering så betyder 64 kB 4-set associativ cache att man först måste slå upp TLB, sen kan man börja uppslagning i L1I$. Inte bra för latens!
Förklaringen jag sett här är att AMD förlitar sig väldigt mycket på att branch-predictorn (som sitter tidigare i pipeline, den är del av front-end medan load/store är back-end) har rätt. Endera utnyttjar man det så att den fysiska adressen är cachad i branch-predictor alt. så gör man en spekulativ TLB-uppslagning redan i front-end. Gissar på det senare, men vet inte vilket som är fallet.
Zen har också en relativt stor mikro-ops cache (kallas ibland L0i$) jämfört med Intel (som införde en sådan i Sandy Bridge). x86 instruktioner är en total katastrof för en front-end att hantera, vilket är orsaken att både AMD och Intel lagt massa kisel på mikro-ops cache. I den cachen kan man ju också ha stoppad in saker för att minska effekten av högre L1I$ latens.
Rent generellt verkar ju båda lösningarna fungera bra. Zen kan uppvisa helt fantastisk prestanda på väldigt små loopar som helt får plats i L0I$, men kan nog vara deras val av L1I$ som ligger bakom varför Zen presterar förvånansvärd dåligt i många script-språk (som typiskt har relativt stor huvudloop som inte på långa vägar får plats i L0I$).
Har sett många exempel på det senare, men inte hittat någon förklaringen i de prestandaräknare som x86 CPUer har. Man kan läsa ut cache-missar, TLB-missar, IPC etc, men går inte att alls få någon insikt i vad som händer i mikro-op cachen från dessa
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Citera flera
Citera
(2)
Skrivet av Paddanx:
Du tänker på 5775c och 5765c Broadwell, som var samma cache som dessa ovan, men de hade ett L4/sDRAM på 128MB också, vilket med tex DX11 får CPUn att få satans jämn och bra prestanda, trots ynka 1600Mhz RAM stöd och stock frekvens på 3,5Ghz
Är en underbar CPU btw i 4-4.2Ghz med den cachen
När man talar om trollen, TechReport postade en artikel just om i7-5775C igår.
Tog ju ett bra tag även för Intel själva att riktigt fatta varför L4$ var i det närmaste värdelös för CPU i majoriteten av alla program, men den gav ju enorm boost i spel.
L4$ har väldigt låg bandbredd för att vara en cache. Den är dual-portad, en för läsning och en för skrivning, båda med kapacitet på 50 GB/s.
Dual-portad design är perfekt för GPU då ofta gör båda parallellt, t.ex. kräver uppdatering i Z-buffer både läsning och skrivning vilket även är fallet för många shaders. Däremot är läsning normalt långt vanligare för en CPU jämfört med skrivning, så 50/50 är rätt obalanserat och i praktiken blir det mer som en cache med ~50 GB/s kapacitet.
L4$ har inte heller alls lika låg latens som L3$, den ligger betydligt närmare RAM än L3$.
Totalt sett uppför sig därför i7-5775C som ett system med väldigt snabbt RAM med väldigt låg latens. 50 GB/s var det inte tal för main-stream om när den här CPUn lanserades, nu är det mer eller mindre standard då det är var man får med DDR4-3200.
Detta har självklart även Intel insett. På desktop blir därför eDRAM väldigt mycket pengar för något som i praktiken inte har något större värde då hastighet på RAM gått upp så mycket.
Däremot har det ett väldigt stort värde på bärbara då snabbt RAM kraftigt ökar "idle" förbrukning, så där vill man inte köra snabbare än 2133/2400 MT/s + iGPU används i långt större utsträckning där. I Skylake designades därför eDRAM om från att vara en L4$ till att just vara en buffert mot RAM. Fördelarna är att man slipper offra 2 MB av L3$ (användes för L4 cache-taggarna i 5x77C) samt att ALLA RAM accesser nu kan nytta eDRAM, d.v.s även disk, nätverk etc.
Numera ligger i7-5775C i genomsnitt efter en i5-8400 i spelprestanda, så inte längre fullt så imponerande. Ändå ingen CPU man kan klaga på (har kvar min som spel CPU), laserad 2015 har 65 W TDP och drar ändå jämnt med 2700X (som utrustas med DDR4-3200) i spel!
Skrivet av Paddanx:
Om du kan hålla samma latens och öka storleken... självklart gör det. Men frågan kommer ju om det var L3 i sig, eller minskningen av L2 som gjorde prestandavinsten. Mao... är 12->14 cykler, när man jämför 3-4Ghz så mycket förlust mot att göra en cache miss pga den var för liten att hålla det man behövde. Skulle tro att där är en fin balans att gå där, och det hänger mer på vad du beräknar, hur bra du kan förutspå data hämtningen (något som spectre/meltdown lär ha skadat en hel del) och hur designen av de omgivande L1 och L3 ser ut.
Meltdown är ju löst redan i CFL-R. Lösningen var väldigt lätt och effektiv då all information redan fanns tillgänglig, lär ha lagt på lite latens för fixen är att validera privligeringsnivån (information som måste finnas i det TLB får tillbaka) INNAN man drar in något CPU-cache.
För en cache-träff kan detta ske parallellt med uppslagning i L1D$, vid en miss kommer ändå latensen dra iväg då man tidigast kan ha en träff i L3$ (Intel har i princip exkluderande policy mellan L1$ och L2$).
Att öka L2$ latensen gjordes antagligen av tre primära skäl:
man ville minska strömförbrukningen, i Skylake minskades även associviteten från 8 till 4 (det är en klar fördel för strömförbrukning)
AVX var ofta bandbreddsbegränsad innan, Skylake fick dubbel L2$ bandbredd, latens och bandbredd har ofta icke-förenliga designkrav
högre latens tillåter högre klockfrekvenser, kan man öka frekvensen 17 % har man ju kompenserat för latensen
Vidare, för varje högre cache-nivå spelar dock latensen allt mindre roll. Är ju bara det som missar L1$ som påverkas av förändringar i L2$.
Skrivet av Paddanx:
Jag har mao svårt att tro att en dubblering av L2 inte kommer ha en markant påverkan på både priset på CPUn, samt latensen på data i den. Men om det görs måste ju uppoffringarna som görs vara värda detta. Och som man kan se när man tittar på bara snabbare RAM latens påverkar dagens CPUer så vet jag inte... där kan du tjäna mycket på att få ner 1ns latens i rätt miljö.
Zen har ju 64 kB L1I$ och 512 kB L2$, så någon gigantisk skillnad på priset lär det inte göra.
Skrivet av Paddanx:
Har dock svårt att tro det är energieffektivt... för minne äter ström. Dessa kretsar måste vara igång 100% när kärnan är igång. Och ska du starta upp och stänga av dem från IDLE, måste de antingen vara igång (med data redo), eller stängas av och sedan fyllas igen (vilket också tar resurser). Så det blir väl en fråga om du kan få upp effektiviteten på hela CPUn för att vinna det tillbaka.
Cache är väldigt energieffektivt. Kostar långt mindre ström att hantera en minnesaccess från cache jämfört med att hantera den ur RAM.
SRAM drar i princip ingenting (mikrowatt) när det inte används då det inte behöver skrivas om hela tiden. Är bara i de djupaste C-state (tror det är C4 och uppåt) man flushar cache, skulle vara kontraproduktivt både för prestanda och strömförbrukning att göra det i C1/C3 där CPUn spenderar majoriteten av sin "idle" tid när den används.
Problemet är att en uppslagning kommer parallellt läsa på lika många ställen som caches associativitet, det är ett potentiellt problem.
Skrivet av Paddanx:
Att dagens CPUer tvingas tömma cachen hela tiden pga dessa buggar har kanske ändrat förutsättningen för hur den mer effektiva nivån är?
Enda buggen som krävt att cache ska tömmas är väl "L1 Terminal Fault" (som för övrigt är fixad i CFL-R)?
Både Windows och Linux har valt allt INTE applicera motmedel mot denna som förval då den i bara kan utnyttjas i väldigt speciellt lägen som i praktiken bara existerar i vissa server-fall.
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Citera flera
Citera
(2)
Skrivet av Yoshman:
Numera ligger i7-5775C i genomsnitt efter en i5-8400 i spelprestanda, så inte längre fullt så imponerande. Ändå ingen CPU man kan klaga på (har kvar min som spel CPU), laserad 2015 har 65 W TDP och drar ändå jämnt med 2700X (som utrustas med DDR4-3200) i spel!
Att en CPU som klassades som värdelös, 3 år senare kan i stock (vilket åter är vad de mäter) hänga med 3 generationers nyare CPU, med 6/6 kärnor vs 4/8 där nyare CPUn har högre frekvens är faktiskt rätt imponerande. Alla 2600k, alla 4790k osv måste ju klockas djuret ur för att hänga med. Denna kan du köra med stock kylaren, även i 4Ghz+, och du slipper dyrt DDR4 RAM.
Att Intel inte designat dens cache "optimalt" är ju förklarligt... ingen visste att den skulle göra det den gjorde. Men det jag har svårt att begripa är... varför göra en 8-core, 16 trådig 200W CPU för "spel-optimering" för 6000kr... istället för att ta en 8400, med HT, och faktiskt göra en optimal SRAM lösning på den. Nu vet man ju var som sker, och kan optimera det. Hade gärna varit intresserad av en 65W upplåst 12 trådig, L4 bestyckad Coffee Lake med denna fördel. Betalar gärna för det, men inte för en 9900k kokplatta.
Lustiga är att jämför folk AMD kort vs Nvidia, klagas det jämt på att du får sämre prestanda med mer värme ur AMD korten. Men tydligen är det en "bättre" lösning när man tittar på Intel CPUer, istället för att göra dem mer effektiva på en specifik del... Känns... väldigt kapp-vändande i blåsvädret.
Jag vidhåller att detta är utan tvekan den bästa Intel CPUn på 5+ år... enda saken som slår den i vettig investering i övrigt är 2600k, men då är det mer än 5 år sedan. Men Skylake och allt efter... är inget mer än P4 Prescott kokare imho.
Därför intresserade dock lite cache förändringen mig, för det låter som att Intel åter jobbar på att effektivisera, istället för att överklocka det man har.
Skrivet av Yoshman:
För en cache-träff kan detta ske parallellt med uppslagning i L1D$, vid en miss kommer ändå latensen dra iväg då man tidigast kan ha en träff i L3$ (Intel har i princip exkluderande policy mellan L1$ och L2$).
Att öka L2$ latensen gjordes antagligen av tre primära skäl:
man ville minska strömförbrukningen, i Skylake minskades även associviteten från 8 till 4 (det är en klar fördel för strömförbrukning)
AVX var ofta bandbreddsbegränsad innan, Skylake fick dubbel L2$ bandbredd, latens och bandbredd har ofta icke-förenliga designkrav
högre latens tillåter högre klockfrekvenser, kan man öka frekvensen 17 % har man ju kompenserat för latensen
Vidare, för varje högre cache-nivå spelar dock latensen allt mindre roll. Är ju bara det som missar L1$ som påverkas av förändringar i L2$.
Zen har ju 64 kB L1I$ och 512 kB L2$, så någon gigantisk skillnad på priset lär det inte göra.
Om nu det är fördelaktigt... och inte skiljer på priset... varför har man inte gjort detta tidigare?
Någon förklaring finns där ju.
Skrivet av Yoshman:
Cache är väldigt energieffektivt. Kostar långt mindre ström att hantera en minnesaccess från cache jämfört med att hantera den ur RAM.
SRAM drar i princip ingenting (mikrowatt) när det inte används då det inte behöver skrivas om hela tiden. Är bara i de djupaste C-state (tror det är C4 och uppåt) man flushar cache, skulle vara kontraproduktivt både för prestanda och strömförbrukning att göra det i C1/C3 där CPUn spenderar majoriteten av sin "idle" tid när den används.
Problemet är att en uppslagning kommer parallellt läsa på lika många ställen som caches associativitet, det är ett potentiellt problem.
Okej, antog att det ändrats mycket. För jag minns diskussioner för läääänge sedan om att cache var problem för hur törstig en CPU var. Detta var ju dock på tidigt x86 tid, och mycket ha ju ändrats i power-states.
Skrivet av Yoshman:
Enda buggen som krävt att cache ska tömmas är väl "L1 Terminal Fault" (som för övrigt är fixad i CFL-R)?
Både Windows och Linux har valt allt INTE applicera motmedel mot denna som förval då den i bara kan utnyttjas i väldigt speciellt lägen som i praktiken bara existerar i vissa server-fall.
Buggen finns dock ändå där... och man valt att inte laga den pga man bedömer prestandaförlusten vs risken
Citera flera
Citera
Skrivet av Paddanx:
Att en CPU som klassades som värdelös, 3 år senare kan i stock (vilket åter är vad de mäter) hänga med 3 generationers nyare CPU, med 6/6 kärnor vs 4/8 där nyare CPUn har högre frekvens är faktiskt rätt imponerande. Alla 2600k, alla 4790k osv måste ju klockas djuret ur för att hänga med. Denna kan du köra med stock kylaren, även i 4Ghz+, och du slipper dyrt DDR4 RAM.
Att Intel inte designat dens cache "optimalt" är ju förklarligt... ingen visste att den skulle göra det den gjorde. Men det jag har svårt att begripa är... varför göra en 8-core, 16 trådig 200W CPU för "spel-optimering" för 6000kr... istället för att ta en 8400, med HT, och faktiskt göra en optimal SRAM lösning på den. Nu vet man ju var som sker, och kan optimera det. Hade gärna varit intresserad av en 65W upplåst 12 trådig, L4 bestyckad Coffee Lake med denna fördel. Betalar gärna för det, men inte för en 9900k kokplatta.
Fast eDRAM är väl ändå rätt meningslöst på desktop numera? Fördel är ju att man får samma effekt som snabba minnen. Under lång tid hände väldigt lite med hastigheten på RAM, under de senaste tre åren har vi haft en rasande utveckling.
i7-5775C stod sig bra i spel (men i princip bara i spel) mot i7-6700K när den senare körde DDR4-2133. Med DDR4-3200 lär redan i7-6700K vara lika bra eller bättre oavsett last (förvånande hur många som missade hur mycket IPC gick upp för heltalsberäkningar med Skylake...).
Så vad vore poängen med eDRAM på desktop idag? eDRAM är relativt dyrt, om det inte ger något i majoriteten av applikationer (vilket är fallet, har just nu totalt 3 CPUer med eDRAM och jämfört dem mot versioner utan eDRAM)?
Stora fördelen eDRAM är för iGPU samt i fall där man har väldigt mycket I/O (vilket är fallet för mig i jobbet). Ovanpå det får NUC/bärbara fördelen av att kunna använda DDR4-2133/2400 och ändå uppföra sig som om man utrustat dem med typ DDR4-3200 fast man slipper strömförbrukningen (många NUC:ar har lägre maxförbrukning än de flesta stationära har i "idle" förbrukning).
Skrivet av Paddanx:
Lustiga är att jämför folk AMD kort vs Nvidia, klagas det jämt på att du får sämre prestanda med mer värme ur AMD korten. Men tydligen är det en "bättre" lösning när man tittar på Intel CPUer, istället för att göra dem mer effektiva på en specifik del... Känns... väldigt kapp-vändande i blåsvädret.
Jag vidhåller att detta är utan tvekan den bästa Intel CPUn på 5+ år... enda saken som slår den i vettig investering i övrigt är 2600k, men då är det mer än 5 år sedan. Men Skylake och allt efter... är inget mer än P4 Prescott kokare imho.
Tja, jag är då inte allt för glad över utvecklingen på desktop. Blir en NUC med i7-8559U som ny "jobba-hemma-maskin" (så min fjärde CPU med eDRAM), få se om Zen2 eller Ice Lake medför något roligt.
Men hoppas innerligt att x86 så fort som möjligt blir förpassat till historien, det är just nu en rejäl bromskloss för att ge oss högre prestanda per kärna (och vill man gå multicore finns ännu mer fördelar med 64-bitars ARM).
Skrivet av Paddanx:
Därför intresserade dock lite cache förändringen mig, för det låter som att Intel åter jobbar på att effektivisera, istället för att överklocka det man har.
Jag hade väldigt mycket hellre sett att man lade dubbelt så mycket transistorer per kärna än att man dubblade antalet kärnor. Vet inte vad alla som gapar över att de behöver 8C gör med sina datorer gör på sina maskiner. Kör Cinebench? Har nytta av 8C i mitt jobb, har dock ännu mer nytta av 20-30 % mer prestanda per kärna både hemma och på jobbet.
Tyvärr man börja slå i lite väl många x86-relaterade flaskhalsar, övre gränsen för vad fler transistorer per kärna kan ge är ungefär: prestanda ~ roten-ur(antal transistorer)
Men det är just "upp till". Apple har ändå visat att det är möjligt att få långt högre IPC än vad Skylake har, A12 verkar ju ligga på ~50 % högre IPC. Svårt att veta hur mycket av det som kommer från ARM64 ISA, men en hel del är mikroarkitektur för A12 är 50-100 % "bredare" i både front-end och back-end jämfört med Skylake/Zen.
Optimala i min värld är ju 2-4 riktigt feta kärnor samt 6-8 enklare kärnor för det som skalar riktigt bra + sådant man vill köra i bakgrunden. Här börjar man se uppvaknande i branschen då Apple kört denna och helt dominerat CPU-prestanda på mobiler/pekplattor sedan man släppte sin första "big-core" ARM.
Också svårt att veta vilken frekvens CPUn i artikeln vi kommenterar kör på, men om det är 2,6 GHz så ser IPC ut att ha ökat 15-20 %!
Skrivet av Paddanx:
Om nu det är fördelaktigt... och inte skiljer på priset... varför har man inte gjort detta tidigare?
Någon förklaring finns där ju.
Att L1$ inte ökas har ju att göra med att x86 fortfarande använder 4 kB "pages". Förutsätter att Intel fortfarande kör med VIFT L1D$ även i Ice Lake, får se hur det påverkar strömförbrukning då det kräver 12 set associativ cache.
Om man hade droppat 4 kB "page" stödet borde vi sett patchar i Linux-kärnan för detta. Ice Lake har ju i övrigt rätt fullständigt stöd redan.
I övrigt måste man fundera hur transistorbudget ska användas. Dubblad storlek på L2$ lär i genomsnitt maximalt ge några procent högre IPC, det är därför bara vettigt om man inte har någon annanstans att lägga dessa transistorer med bättre utdelning. Åter igen, jämför Apples CPU.
Är först i senaste vändan man riktigt drog upp cache-storleken, ändå är denna generation en av de mindre ökningarna Apple haft i prestanda per kärna på många år. Man börjar nog se slutet på hur pass hög IPC ARM64 rimligen kan ge, eller i bästa fall tog man bara en paus i sin förbättring av mikroarkitektur och passade på att justera saker som cache.
Största problemet med cache tror jag är att det tar relativt stor kretsyta, så att öka cache är en av de sista saker man tar till. Första steget ska alltid vara att optimera front-end och back-end. Från Nehalem till Skylake fördubblades storleken på out-of-order fönstret, det är långt bättre användning av transistorer jämfört med 256 kB -> 512 kB L2$.
Men allt ser i något läge dimishing-returns, rätt säker att front-end börjar bli en rätt rejäl flaskhals på Intels x86. Problemet här: är extremt svårt att avkoda x86 instruktioner p.g.a. av variabel storlek, prefix som ändrar betydelsen av efterföljande instruktion, nästan alla instruktioner ändrar flag-fältet (för de som programmerar, ungefär som konstant skriva till en delad variabel i multitrådade program...).
Jämför med problemet ARM-nissarna ska lösa här. Alla instruktioner är fyra bytes, så trivialt att avkoda upp till 6-7 instruktioner per cykel vilket är var Apple numera gör. Zen tar upp till 4 st, Skylake tar upp till fyra 4 i normalfallet samt 5 i speciella fall). De flesta ARM instruktioner påverkar inte flag-fältet, samt de är icke destruktiva (d.v.s tar ett separat register för resultatet, x86 skriver över ett av indata registren).
Skrivet av Paddanx:
Buggen finns dock ändå där... och man valt att inte laga den pga man bedömer prestandaförlusten vs risken
Buggen är ju lagad i CFL-R (samt Whiskey Lake, Cascade Lake fixar även spectre variant 2).
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Citera flera
Citera
(1)
Skrivet av Yoshman:
Fast eDRAM är väl ändå rätt meningslöst på desktop numera? Fördel är ju att man får samma effekt som snabba minnen. Under lång tid hände väldigt lite med hastigheten på RAM, under de senaste tre åren har vi haft en rasande utveckling.
i7-5775C stod sig bra i spel (men i princip bara i spel) mot i7-6700K när den senare körde DDR4-2133. Med DDR4-3200 lär redan i7-6700K vara lika bra eller bättre oavsett last (förvånande hur många som missade hur mycket IPC gick upp för heltalsberäkningar med Skylake...).
Så vad vore poängen med eDRAM på desktop idag? eDRAM är relativt dyrt, om det inte ger något i majoriteten av applikationer (vilket är fallet, har just nu totalt 3 CPUer med eDRAM och jämfört dem mot versioner utan eDRAM)?
Stora fördelen eDRAM är för iGPU samt i fall där man har väldigt mycket I/O (vilket är fallet för mig i jobbet). Ovanpå det får NUC/bärbara fördelen av att kunna använda DDR4-2133/2400 och ändå uppföra sig som om man utrustat dem med typ DDR4-3200 fast man slipper strömförbrukningen (många NUC:ar har lägre maxförbrukning än de flesta stationära har i "idle" förbrukning).
Poängen är att jag kan få spelprestandan jag vill ha, utan 200W CPU, och att min desktop prestanda är lika snabbt oavsett haswell som coffee-lake, så jag lägger inte 1 enda krona på att bättra detta. (Märkte mer skillnad med att byta DNS eller ha en SSD än jag gjort på 5+ år av desktop CPU).
Vill jag har fler trådar, köper jag en AMD CPU istället.
Jag vill ha en spel-CPU, hårt optimerad för detta, och inte desktop.
Tittar du på varför folk ens köper Intel, är det för de vill ha spel-prestandan... inte för de vill ha öppnat Edge en bråkdel av sekunden snabbare.
Så du borde veta "varför". Och om folk är villiga att betala 6000kr för en CPU som inte kommer ge mycket nytta över en överklockad 8700k, så... förstår jag inte varför nu av alla tidpunkter, du anser något "dyrt"... när tydligen 8550U var värt pengarna över 8350U "oavsett pris".
Lustigt hur kostnader kan förklaras när man har egna behov och motiv, eller hur?
Jag äger 2st 5775c trots att de var dyra, och ångrar inte dem. Varför skulle jag då inte vilja ha en 6-core version?
Skrivet av Yoshman:
Tja, jag är då inte allt för glad över utvecklingen på desktop. Blir en NUC med i7-8559U som ny "jobba-hemma-maskin" (så min fjärde CPU med eDRAM), få se om Zen2 eller Ice Lake medför något roligt.
Lustigt att eDRAM var för dyrt ovan
Skulle nog säga att det går rätt enkelt att göra eDRAM på en 6-core för mindre än vad Intel vill ha för 2-cores till, som inte tillför något de heller. Du kan ju jämföra 8700ks lanseringspris vs 9900ks. Blir en hel del eDRAM för de pengarna
Skrivet av Yoshman:
Men hoppas innerligt att x86 så fort som möjligt blir förpassat till historien, det är just nu en rejäl bromskloss för att ge oss högre prestanda per kärna (och vill man gå multicore finns ännu mer fördelar med 64-bitars ARM).
Så du har börjat förstå vad jag mena med att vi behöver börja om nu... kul.
Skrivet av Yoshman:
Jag hade väldigt mycket hellre sett att man lade dubbelt så mycket transistorer per kärna än att man dubblade antalet kärnor. Vet inte vad alla som gapar över att de behöver 8C gör med sina datorer gör på sina maskiner. Kör Cinebench? Har nytta av 8C i mitt jobb, har dock ännu mer nytta av 20-30 % mer prestanda per kärna både hemma och på jobbet.
Nu har vi inte ditt jobb, eller ditt intresse hemma.
Men nej, jag ser ingen poäng med 8-core heller. 6-core kan jag dock, för jag märker att spel kan använda 8-trådar rätt bra, och då lämnar det inte mycket över till annat som jag har igång samtidigt. Men jag behöver inte 5Ghz... vill hellre ha 4-4,5och svalt med högsta möjliga effektivitet (låg latens/snabbt RAM) och SSDer, inte HDDs.
Skrivet av Yoshman:
Tyvärr man börja slå i lite väl många x86-relaterade flaskhalsar, övre gränsen för vad fler transistorer per kärna kan ge är ungefär: prestanda ~ roten-ur(antal transistorer)
Men det är just "upp till". Apple har ändå visat att det är möjligt att få långt högre IPC än vad Skylake har, A12 verkar ju ligga på ~50 % högre IPC. Svårt att veta hur mycket av det som kommer från ARM64 ISA, men en hel del är mikroarkitektur för A12 är 50-100 % "bredare" i både front-end och back-end jämfört med Skylake/Zen.
Optimala i min värld är ju 2-4 riktigt feta kärnor samt 6-8 enklare kärnor för det som skalar riktigt bra + sådant man vill köra i bakgrunden. Här börjar man se uppvaknande i branschen då Apple kört denna och helt dominerat CPU-prestanda på mobiler/pekplattor sedan man släppte sin första "big-core" ARM.
Också svårt att veta vilken frekvens CPUn i artikeln vi kommenterar kör på, men om det är 2,6 GHz så ser IPC ut att ha ökat 15-20 %!
Att L1$ inte ökas har ju att göra med att x86 fortfarande använder 4 kB "pages". Förutsätter att Intel fortfarande kör med VIFT L1D$ även i Ice Lake, får se hur det påverkar strömförbrukning då det kräver 12 set associativ cache.
Om man hade droppat 4 kB "page" stödet borde vi sett patchar i Linux-kärnan för detta. Ice Lake har ju i övrigt rätt fullständigt stöd redan.
I övrigt måste man fundera hur transistorbudget ska användas. Dubblad storlek på L2$ lär i genomsnitt maximalt ge några procent högre IPC, det är därför bara vettigt om man inte har någon annanstans att lägga dessa transistorer med bättre utdelning. Åter igen, jämför Apples CPU.
Är först i senaste vändan man riktigt drog upp cache-storleken, ändå är denna generation en av de mindre ökningarna Apple haft i prestanda per kärna på många år. Man börjar nog se slutet på hur pass hög IPC ARM64 rimligen kan ge, eller i bästa fall tog man bara en paus i sin förbättring av mikroarkitektur och passade på att justera saker som cache.
Det jag dock tror behövs är att sluta tänka CPUn som "one size fits all". Sluta se nästa generation som måste vara bättre på allt och alla. Utan gör istället optimerade CPUer, för specifika laster. Precis som du vill ha en typ av CPU ovan, vill spelare ha en CPU som ger bäst prestanda i spel, oavsett vad man får offra i övrigt.
Man ser ju också att Intel fått slut på idéer när man släpper en CPU som är ett hån mot 95W TDP... och kräver mer än 4-fasers moderkort bara för att kunna hålla den turbo de alltid använt. Och varför? För att den ska verka snabbare? För ja... 5Ghz 1-2 core är ju snabbare. Men... du kan ju köra detta i många CPUer tidigare, med samma prestanda.
Så jag hade gärna sett olika CPUer, för olika behov. Där en har kanske färre kärnor, men maximal frekvens. Andra har eDRAM för dens behov med låg TDP, osv. Tror att för att optimera mer, måste man optimera dem separat.
Skrivet av Yoshman:
Största problemet med cache tror jag är att det tar relativt stor kretsyta, så att öka cache är en av de sista saker man tar till. Första steget ska alltid vara att optimera front-end och back-end. Från Nehalem till Skylake fördubblades storleken på out-of-order fönstret, det är långt bättre användning av transistorer jämfört med 256 kB -> 512 kB L2$.
Men allt ser i något läge dimishing-returns, rätt säker att front-end börjar bli en rätt rejäl flaskhals på Intels x86. Problemet här: är extremt svårt att avkoda x86 instruktioner p.g.a. av variabel storlek, prefix som ändrar betydelsen av efterföljande instruktion, nästan alla instruktioner ändrar flag-fältet (för de som programmerar, ungefär som konstant skriva till en delad variabel i multitrådade program...).
Jämför med problemet ARM-nissarna ska lösa här. Alla instruktioner är fyra bytes, så trivialt att avkoda upp till 6-7 instruktioner per cykel vilket är var Apple numera gör. Zen tar upp till 4 st, Skylake tar upp till fyra 4 i normalfallet samt 5 i speciella fall). De flesta ARM instruktioner påverkar inte flag-fältet, samt de är icke destruktiva (d.v.s tar ett separat register för resultatet, x86 skriver över ett av indata registren).
Lite därför är det intressant också att man gör denna ändring nu. För det verkar som att man just träffat på den "sista saker man tar till". Och då ser jag inte det som fel att göra det, utan mer som att man insett att alla andra vägar har gjorts, och det är då fullt naturligt att gå denna väg.
X86 lär inte försvinna på 20 år dock, så samtidigt som man letar en ny väg, måste man kanske hårt optimera det man har, genom att offra en prestanda för en annan. Kan iaf säga att... för 99% av oss, är nog desktop snabbt nog. Det är lite andra ställen, som tex 1% low framedrops som många fler har nytta av nu
Skrivet av Yoshman:
Buggen är ju lagad i CFL-R (samt Whiskey Lake, Cascade Lake fixar även spectre variant 2).
Så det är "en" bugg... wow
De hittar dock 2 nya i takten de lagar 1.
Och Whiskey osv är inte på kartan för de flesta av oss. Vi sitter än på som någon valt att kalla det... Skylake 4.
Citera flera
Citera
(1)
Skrivet av Paddanx:
Poängen är att jag kan få spelprestandan jag vill ha, utan 200W CPU, och att min desktop prestanda är lika snabbt oavsett haswell som coffee-lake, så jag lägger inte 1 enda krona på att bättra detta. (Märkte mer skillnad med att byta DNS eller ha en SSD än jag gjort på 5+ år av desktop CPU).
Rätt säker på att du fånar dig i det här läget.
Du kan få >= prestanda i precis allt för 65 W TDP med i5-8400. eDRAM ger ingen vettig boost nu när RAM-hastigheterna har ökat så pass mycket. i5-8400 är ju med i TechReports nya jämförelse av i7-5775C, tänk då på att man bara testar spel. i7-5775C var långsammare än i7-6700K i de flesta "vanliga" applikationer även när den senare körde DDR4-2166.
Om du inte märker någon skillnad på CPU-byte säger det mest något om vad du använder din dator till. Själv märkte jag skillnad mellan de R5-1600 och i7-6770HQ jag hade tidigare i fall där enkeltrådprestanda gör skillnad, det är kanske ~30 % mellan dessa (till den senares fördel).
Skrivet av Paddanx:
Vill jag har fler trådar, köper jag en AMD CPU istället.
Jag vill ha en spel-CPU, hårt optimerad för detta, och inte desktop.
Tittar du på varför folk ens köper Intel, är det för de vill ha spel-prestandan... inte för de vill ha öppnat Edge en bråkdel av sekunden snabbare.
Finns faktiskt de som jobbar på sin dator. Är väldigt på det klara med av en i7-8559U kommer göra bättre och vad den kommer göra sämre än den R7-2700X jag nu använder för motsvarande uppgift (kommer behålla AMD-systemet, men ställer det nog på jobbet, avskyr desktop PC).
Gör även saker där en Optane-disk kan vara vettig, man får ju in en NVMe disk + SATA disk i Bean-canyon NUC:arna.
Skrivet av Paddanx:
Så du borde veta "varför". Och om folk är villiga att betala 6000kr för en CPU som inte kommer ge mycket nytta över en överklockad 8700k, så... förstår jag inte varför nu av alla tidpunkter, du anser något "dyrt"... när tydligen 8550U var värt pengarna över 8350U "oavsett pris".
Lustigt hur kostnader kan förklaras när man har egna behov och motiv, eller hur?
Jag äger 2st 5775c trots att de var dyra, och ångrar inte dem. Varför skulle jag då inte vilja ha en 6-core version?
Ångrar inte heller 5775C, är lysande som speldator. Framförallt då den sitter i en relativt litet chassi.
Du vill inte ha en 6-kärnors version därför att när du stoppar i DDR4-3200 är eDRAM helt meningslöst
eDRAM, så som det används i Skylake, är vettigt om man vill ha riktigt låg strömförbrukning (NUC eller laptop nivå) eller om man har hyfsat extrema I/O-krav (extrema jämfört med svensson, inte jämfört med en större server).
Skrivet av Paddanx:
Lustigt att eDRAM var för dyrt ovan
Skulle nog säga att det går rätt enkelt att göra eDRAM på en 6-core för mindre än vad Intel vill ha för 2-cores till, som inte tillför något de heller. Du kan ju jämföra 8700ks lanseringspris vs 9900ks. Blir en hel del eDRAM för de pengarna
Nu säger definitivt inte listpriset hela sanningen, t.ex. så listas i7-8559U för 431 USD, vilket känns rätt orimligt då en NUC med den CPUn går att köpa för ~5500 SEK inklusive moms.
Men eDRAM på dagens desktop-modeller är rätt dyrt räknat i förväntad prestandaökning per krona, förutsatt att du inte tänker köra med DDR-2400 eller långsammare.
Finns absolut snabbare eDRAM, flaskhalsen är nog mer hur eDRAM kopplas till CPUn idag. Självklart skulle man kunna ta fram en speciellt modell med eDRAM, men DET blir rejält dyrt om man inte kan lägga ut FoU-kostnaden över relativt många sålda enheter.
Skrivet av Paddanx:
Så du har börjat förstå vad jag mena med att vi behöver börja om nu... kul.
Det var ett riktigt lågvattenmärke...
Det vi haft åsiktsskillnaden om tidigare är om Intel behöver designa om Core (som har DNA tillbaks till PentiumPro). Finns fortfarande ingen annan x86-design som matchar Skylake i utfört arbetet per klockcykel och maxfrekvens.
Av det lilla som läckt ut finns ju indikationer på att Ice Lake kan komma att få en större ökning i IPC över Skylake än vad Zen2 får över Zen.
D.v.s. står fortfarande fast vid att Core är rätt mycket så "perfekt" en x86 design kan bli. Apple har dock med brutal övertydlighet visat att tar man bort "x86" ur ekvationen kan man göra något väsentligt bättre.
Intel lär nog knappast släppa en 64-bitars ARM, men de verkar inte försöka gömma allt för mycket att man jobbar med RISC-V. RISC-V och ARM64 lanserades båda runt 2011 och är båda en så "perfekt" instruktionsuppsättning vi är kapabla att designa just nu. AMD bör nog kraftigt överväga att ta upp sitt ARM-spår igen, Zen var ju tänkt att både bli en x86 och en 64-bitars ARM (K12) initialt (finns en del designval i back-end på Zen som känns lite udda för en x86 men helt logiska om man även skulle gjort en ARM).
Skrivet av Paddanx:
Det jag dock tror behövs är att sluta tänka CPUn som "one size fits all". Sluta se nästa generation som måste vara bättre på allt och alla. Utan gör istället optimerade CPUer, för specifika laster. Precis som du vill ha en typ av CPU ovan, vill spelare ha en CPU som ger bäst prestanda i spel, oavsett vad man får offra i övrigt.
Bara ett mindre problem med detta... Priset för att ta fram en krets har inte haft någon trevlig utveckling de senaste noderna, allt pekar på att det kommer bli väsentligt värre för varje nod framöver.
Ett exempel är att Qualcomm faktiskt _backade_ ett halvsteg i deras senaste Snapdragon, man gick från TSMC/Samsung 10 nm till Samsungs 11 nm (som i praktiken är för deras 14 nm vad Intels 14 nm++ är för Intels 14 nm). Inte sett något officiellt från Qualcomm kring detta, men gissningarna ligger på att man inte ansåg prislappen motiverande eventuella fördelar.
Men precis det du skriver ser vi ju hända på bred front i systemkretsarna för smarta mobiler, rätt säker att det kommer leta sig in i bärbara relativt snart.
Apple, Qualcomm, Huawei, m.fl. har stoppat in ett par "high-end" CPUer för interaktiva laster, ett gäng "efficiency cores" för bakgrundsuppgifter, iGPU för grafik, NPU (neural network processor) för maskininlärning samt DSP för bildhantering.
Där är en vettig framtid. CPU-delen ska göra så lite som möjligt, den ska hantera uddafallen, de fall man inte tänkte på innan samt det som är latenskänsligt. Det är styrkorna i en CPU. Men allt som kan köras på mer specialiserad kisel ska lyftas bort från CPU, blir väsentligt högre beräkningseffektivitet på det sättet.
Problemet innan har varit att kunna programmera sådana system. Är fortfarande ett problem, men man gör trots allt verkliga framsteg inom detta (jämfört med tidigare där det mesta var varmluft).
Att ta fram en fungerande high-end x86 är ett jätteprojekt. Finns en anledning varför AMD försöker täcka alla marknader med en enda design, något som kommer ge kompromisser. Inte ens Intel anser sig ha råd med mer än tre spår,
Atom för NAS, mikroservers samt bärbara i budgetsegmentet.
S, H, U och Y-serien som alla är samma CPU för olika konsumentsegment.
X-serien samt Xeon som riktar sig mot servers (X-serien känns just nu rätt meningslös, än mer så efter 9900K).
Även här finns stora anledningar till att skrota x86. Både AMD och Intel var chanslösa från start på mobilsidan, inte för att x86 inte kan göras energieffektiv utan därför tiden att designa och validera en x86 krets tar så mycket längre tid än att designa och validera en krets med en "vettig" ISA (fast är gränsfall om 32-bitars ARM är "vettig", 64-bitars ARM och RISC-V är definitivt vettiga) att inte ens Intels FoU hade någon chans.
Om det visar sig att Ice Lake trots allt har 15-20 % högre IPC har jag svårt att tro man kan riktigt hålla frekvenserna på 10 nm. Och det må vara en imponerande ökning för dagens x86, men på ARM sidan såg man Apples A12 som lite "meh" då den bara hade ~15 % högre prestanda per kärna än tidigare.
ARM själva lovar ju ~30 % ökning i enkeltrådprestanda per år de närmaste tre åren. Man ligger numera någonstans mellan Zen och Skylake i IPC med Cortex A76. Är fortfarande en bit kvar då man räknar med klockfrekvenser på 3,0-3,5 GHz.
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Citera flera
Citera
(1)

Skrivet av Paddanx:
Poängen är att jag kan få spelprestandan jag vill ha, utan 200W CPU, och att min desktop prestanda är lika snabbt oavsett haswell som coffee-lake, så jag lägger inte 1 enda krona på att bättra detta. (Märkte mer skillnad med att byta DNS eller ha en SSD än jag gjort på 5+ år av desktop CPU).
Jag bytte nyligen, ofrivilligt, från Haswell-E till Coffee Lake och tycker det är en påtaglig uppgradering. Det är kanske inte vad jag sett som värt pengarna, men när gamla systemet pajade så... en definitiv uppgradering.
Skickades från m.sweclockers.com
Citera flera
Citera
Skrivet av Yoshman:
Rätt säker på att du fånar dig i det här läget.
Nej. Jag fånar mig inte.
Jag har bara andra önskemål än du har.
Skrivet av Yoshman:
Du kan få >= prestanda i precis allt för 65 W TDP med i5-8400. eDRAM ger ingen vettig boost nu när RAM-hastigheterna har ökat så pass mycket. i5-8400 är ju med i TechReports nya jämförelse av i7-5775C, tänk då på att man bara testar spel. i7-5775C var långsammare än i7-6700K i de flesta "vanliga" applikationer även när den senare körde DDR4-2166.
Och om inte mer cache spela någon roll, hade inte Intel ökat den heller.
Med tanke på att det görs eDRAM CPUer även med Kaby, så förstår jag inte varför du anser dig veta bättre än Intel nu.
Men du älskar dina vanliga applikationer som argument, trots att de är noll roll, meningslösa och inget som intresserar mig. Köp en AMD om du vill köra dessa prisvärt....
Skrivet av Yoshman:
Om du inte märker någon skillnad på CPU-byte säger det mest något om vad du använder din dator till. Själv märkte jag skillnad mellan de R5-1600 och i7-6770HQ jag hade tidigare i fall där enkeltrådprestanda gör skillnad, det är kanske ~30 % mellan dessa (till den senares fördel).
För du använder enkelttråd prestandan... jag gör det inte.
Inget jag kör är tungt 1-tråd. Antingen är det flertrådigt, eller 1-tråd lätt jobb som tom en 3Ghz gammal C2Duo klara av. Finns ingen vinst för mig.
Skrivet av DasIch:
Jag bytte nyligen, ofrivilligt, från Haswell-E till Coffee Lake och tycker det är en påtaglig uppgradering. Det är kanske inte vad jag sett som värt pengarna, men när gamla systemet pajade så... en definitiv uppgradering.
Skickades från m.sweclockers.com
Lite det där "värt pengarna" som är problemet. Ingen tvekan på att en graf, eller 1 FPS eller 2 kan ges mer, men det är inte värt pengarna. Problemet med 5775c är eg dens låga frekvens i stock. Men det är enkelt att dra upp till 4Ghz. När du gör det, är du i samma lika i IPC som både 8400 och många andra CPUer. Och även om du inte håller 65W när man gör det, så är det inte svårt att kyla vs en stock 4790k eller nyare. Det är trots allt 14nm i broadwell också, så skillnaden är inte så stora i praktiken.
När väl eDRAMet kommer in i bilden dock, får denna CPUn fortfarande sin boost, och att man åter jämför tester med den i stock, säger bara att man inte insett fördelen den har över tex 8400... den kan klockas
Kan tillägga @Yoshman att vill du sälja din, blir du förvånad hur mycket du kan få och hur enkelt det är. Folk gapar efter dessa CPUer... så antingen behåll den och va gla, eller sälj och köp dina dyra nya meningslösa leksaker.
Citera flera
Citera
Hårdvara
- Igår Airtec Pro Type1 – batteridrivet alternativ till tryckluft på burk 44
- Igår Nu stiger hårddiskpriserna med uppemot 10 procent 13
- Igår Analytiker: Apple har överskattat intresset för Vision Pro 50
- 24 / 4 AMD, Nvidia och Intel – vad är det för skillnad mellan grafikkortstillverkarna? 26
- 24 / 4 Testpilot: MSI MPG 271QRX - Färgsprakande OLED i 360 Hz 13
Mjukvara
Datorkomponenter
Ljud, bild och kommunikation
- Microsoft blockerar äldre processorer i Windows 11 24H257
- Nu stiger hårddiskpriserna med uppemot 10 procent13
- Ingen som är taggad på att se nya Dune?, Bioprimär idag 15 sep165
- Posta din hastighet!2442
- Vad lyssnar du på just nu?13892
- Konsumentverket granskar tio nätbutiker som lurat kunder10
- Elbilar - Tråden för intresserade23177
- Telenors router och netgear sammankopplade0
- Torrent funkar inte efter återställning15
- LLama3 eller "Hur kan en språkmodell stapla saker?"41
- Köpes Luftkylning och Fläktar
- Köpes Nvidia Quadro P400,600 eller 620
- Säljes Dell Latitude 7530 15,6”
- Köpes Önskar köpa 6700xt eller 3070
- Säljes Asus Geforce RTX 2070 8GB Strix Gaming OC
- Köpes Köper bärbara datorer, trasiga, utan skärm etc.
- Säljes Lenovo Thinkcentre M73
- Säljes Lenovo Legion Slim 5 14” OLED
- Säljes Asus VG248 24"
- Säljes AMD Ryzen 5 3400G inkl kylare
- Konsumentverket granskar tio nätbutiker som lurat kunder10
- Airtec Pro Type1 – batteridrivet alternativ till tryckluft på burk44
- Nintendo-innehåll tas bort från Garrys Mod15
- Nu stiger hårddiskpriserna med uppemot 10 procent13
- Quiz: Vad kan du om Inet?68
- Analytiker: Apple har överskattat intresset för Vision Pro50
- Microsoft rullar ut Startmenyreklam till alla59
- EU röstar igenom ”rätten att reparera”53
- Viaplay sätter ner foten mot delade konton55
- AMD, Nvidia och Intel – vad är det för skillnad mellan grafikkortstillverkarna?26
