




Ryzen 7 3800X, Asus Prime X370 Pro, 32 GB LPX 3600, Gainward RTX 3060 Ti Ghost, 7 TB SSD + 4 TB HDD
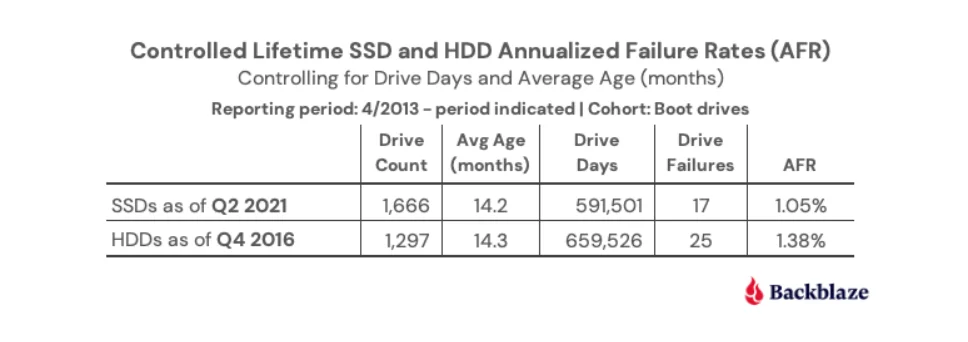
Backblaze visar felstatistik på 190 000 lagringsenheter
Visa signatur


Senast redigerat

Senast redigerat
Visa signatur
Här hade jag en historik sen 1990-talet, men den blev tillslut för lång. Aktiva maskiner 2022-framåt:
Work/Play/Everythingstation: AMD Epyc 7443p, Pop OS host, Win10 + Linux guests (KVM/Qemu)
Work/Play nr 2: AMD Phenom II 1090t, Debian + Win 10 (dual boot)
Server x3: Epyc 7252 (TrueNAS Core), Atom 2550 (FreeBSD, backup), Opteron 6140 (Ubuntu, off prem backup)
Retrohörna under uppbyggnad: Dual Pentium Pro 200MHz, Pentium P54C 90MHz, Gravis Ultrasound MAX

Visa signatur
CPU: 5600x
GPU: 3080
RAM: 32GB
Sluta gömma din identitet, skaffa en till istället

Visa signatur
Gamingrigg: MEG x570 ACE, 5950X, Ripjaws V 32GB 4000MT/S CL16, 6800XT Red Devil LE, HX1200i.
Laptop: XPS 9570 x GTX 1050 x 8300h + 16GB Vengeance 2666Mhz + Intel AX200
Valheim server: i7-8559 + Iris Plus 655 + 32GB + 256GB
Printers? Yes. Ender 5, Creality LD-002R, Velleman VM8600, Velleman K8200
Visa signatur
Gamingrigg: MEG x570 ACE, 5950X, Ripjaws V 32GB 4000MT/S CL16, 6800XT Red Devil LE, HX1200i.
Laptop: XPS 9570 x GTX 1050 x 8300h + 16GB Vengeance 2666Mhz + Intel AX200
Valheim server: i7-8559 + Iris Plus 655 + 32GB + 256GB
Printers? Yes. Ender 5, Creality LD-002R, Velleman VM8600, Velleman K8200

Visa signatur
Gamingrigg: MEG x570 ACE, 5950X, Ripjaws V 32GB 4000MT/S CL16, 6800XT Red Devil LE, HX1200i.
Laptop: XPS 9570 x GTX 1050 x 8300h + 16GB Vengeance 2666Mhz + Intel AX200
Valheim server: i7-8559 + Iris Plus 655 + 32GB + 256GB
Printers? Yes. Ender 5, Creality LD-002R, Velleman VM8600, Velleman K8200


Visa signatur
Dator: ASUS Pro WS X570-Ace - Ryzen 5 3600X vattenkyld - 4x8GB GSkill Ripjaws V 3600MHz - PNY GTX 980 Ti XLR8 OC vattenkyld - ASUS Xonar DX - Corsair Force MP600 1 TB - Corsair AX750 - Fractal Design Define S
NAS: Synology DS716+ - 2x4TB HGST MegaScale DC 4000.B Router: Netgear R7000 - AdvancedTomato Firmware
