

Varje gång man påpekar att Alder lake är bättre än Apple M1 i dom flesta testerna blir man ignorerad.
Apple evangelisterna blir helt tysta.
Inte ens ett svar, varför höjer inte Apple frekvenserna så dom blir snabbare än intel.
Är inte det viktigt för Apple att visa att man är bra i cinebench som många brukar spela?
Är svaret, dom kan inte…??
Edit: Då kanske ni tänker, men M1 har ju bättre batteri tid, hur ofta är ni o pluggade med laptopen?
Edit2: jag citerade till och med eran favorit Yoshman, kanske den främsta Apple evangelisten på detta forum.
Att "gissa" kring vad Apple tänker göra har åtskilliga gånger visat sig vara betydligt svårare än att "gissa" vad t.ex. Intel/AMD tänker göra framöver. Så det är svårare att göra någon vettig spekulation kring dem.
Vidare, Alder Lake desktop är snabbare än M1, är väl inte så mycket att diskutera där.
Men hur ser det ut för bärbara, vilket är det enda Apple har designat Apple-silicon för så här långt? Där är det rätt mycket spel mot ett mål för tillfället, hoppet där (om man gillar Windows) är nog sannolikt Qualcomm (tack vare deras köp av Nuvia) och inte Intel/AMD.
Går det klocka Apple CPU högre? Med 100 % säker: ja. Men "ingen" (förutom Apple själva) vet exakt hur effekt/frekvens kurvan ser ut, den skiljer sig rejält mellan olika mikroarkitekturer. Se bara på Zen3 vs Golden Cove, Zen3 har (för att vara x86) väldigt bra perf/W ställd mot Golden Cove mellan 4 till ~4,5 GHz. Men kollar man på t.ex. TechPowerUp som även mäter effekt vid enkeltrådprestanda där Zen3 når ~5 GHz medan Golden Cove når strax över 5 GHz ser man att vid dessa frekvenser är det Intel som är den mer effektiva.
Med väldigt nära 100 % sannolikhet går inte M1 att klocka till 5 GHz med mindre än att kyla den med flytande kväve. Dock hopplöst att veta (om man inte har tillgång till Apples lab) hur mycket perf/W droppar vid t.ex. 4,0 GHz (för dit borde man nå då A15 når 3,25 GHz i en telefon (A14 ligger på 2,85 GHz), A15 har "Avalanche" kärnor vilket rimligen även M2 får, A14/M1 kör föregångaren "Firestorm", största skillnaden är att Avalanche har märkart bättre perf/W men är ungefär samma IPC).
MacPro med Apple-silicon väntas ju "snart" (under 2022 om Apple ska hålla sin "två år för att övergå till Apple silicon"), där får vi kanske se vad som är möjligt när man skruvar upp TDP. Fast ryktena där prata om 40 "stora" kärnor, om 4 "stora" M1 kärnor drar ~15 W vid 3,2 GHz kommer 40 kärnor dra ~150 W. Vi kan nog räkna med att "turbo boost" saknas även där, så kanske inte blir mycket snabbare "per-core" prestanda.
Är själv beskviken på M1 Pro/Max just då de inte alls skruvade upp prestanda per kärna. M1 var helt sanslös när den släpptes hösten 2020, <20 W CPU som var snabbare än allt annat på marknaden. Givet att A15 (kretsen i Iphone 13) skruvade upp prestanda per kärna ~10 % och redan fanns på marknaden när M1 Pro/Max släptes gjorde det ännu mer till en besvikelse.
Så ser Alder Lake som snabbaste desktop CPU för tillfället, vi har inte olika åsikter där. Men är själv mäkta trött på vindtunnel-system och är fortfarande imponerad över hur brutalt bra M1 (har en M1 MacMini samt M1 MBA) jämfört mitt PC system (5950X+RTX3090). Visst är den senare snabbare på många saker, men majoriteten av det jag gör går fortfarande snabbare på den helt tysta M1 datorn (vilket inte varit sant om jag istället haft en 12900K då den har 15-20 % bättre enkeltrådprestanda)! Är egentligen bara program som är GPGPU-accelererade med CUDA där det senare systemet riktigt hamnar på en helt annan nivå.
Hade jag köpt ett system idag hade det inte blivit 5950X utan 12900K (eller möjligen 12700K, för 12900K har lite väl galen effekt). Samma åt grabben, köpte en 5600X till hans speldator förra året men i år hade 12600K blivit det självklara valet där.
Och för ha någon relevans till artikeln och det du skriver om batteritid: det är ett område där jag tycker folk borde vara mer kritiskt mot AMD. AMDs PR-avdelning har kommit på ett genidrag: i princip alla prestandatester för bärbara utförs när de körs på nätdrift. Sedan kör man någon webbtest och/eller filmtest på batteri där man mäter drifttid.
Hur optimerar man för det? Jo, man droppar CPU/iGPU prestanda rätt ordentligt när man kör på batteri -> bättre batteritid samt "bra" prestandaresultat då de körs på AC. MBA/MBP har identisk prestanda på batteridrift som AC, Intel ligger normalt inom 90 % medan AMD kan trilla ned betydligt lägre. Ett stort problem Intel/AMD har här är att deras peak-effekt är på en nivå som är skadligt för batterierna, så de är tvungna att göra detta!
Och visst finns det de som primärt använder sin bärbara med nätdrift. För egen del använder jag laptop primärt på batteri då jag använder stationär i normfallet. I det läget är det lite svårt att inte blir "Apple evangelisten" i nuläget, för M1, M1 Pro/Max spelar i en annan liga än Intel/AMD just nu.
Edit: har nu kollat på videon du länkade. Tim på HU har uppenbarligen väldigt dålig koll på MacOS...
Cinebench R23 är en av de mindre dåligt jämförelserna här, det är hyfsat äpplen mot äpplen (bortsett från 45 W mot 75 W). Men det jämför inte riktigt vad man kanske tror då x86_64 versioner är AVX optimerad medan MacOS versionen saknar motsvarande optimeringar (vilket på skulle vara att köra med MacOS accelerate).
Handbreak har samma problem som Cinebench, men här är skillnaden ännu större. x86 versionen har handoptimerade AVX/AVX2 optimeringar och motsvarande saknas i princip helt för ARM64 (instruktionerna finns, men ingen har optimerat då få använder Handbreak på MacOS, de program folk använder kör HW-accelerering för detta och då är detta en av M1 Pro/Max absolut starkaste punkter).
Blender 2.9 är i alla fall M1 "native", men är först Blender 3.1 som får de optimeringar Apple jobbat på och prestanda där är väsentligt bättre på M1 jämfört med tidigare. För x86 finns klara förbättringar med CUDA (var därför 3090 kan rendera BMW scenen på 7s, det är inte fallet i 2.9). Prestanda för CPU-rendering på x86 är dock i princip samma mellan 2.9 och 3.x.
Tidigare körde HU x86 versionen av FL Studio på MacOS, d.v.s. de M1 får emulera x86! De skriver inte vilken version de kör här, den senaste versionen av FL Studio har numera "native stöd" för Apple-silicon. Har själv noll koll på vad detta program faktiskt gör.
Varför utelämnar de M1 för kodkompilering? Det är en av de mer äpplen mot äpplen man kan få mellan x86 och ARM64, är för detta och saker som NodeJS, Java (JVM) och liknande jag primärt gör jämförelserna. Här kom stödet för "native Apple silicon" väldigt snabbt och prestanda är riktigt bra (även mot Alder Lake).
Edit2: finns ett lite större test än videon här
https://www.techspot.com/review/2410-intel-core-i7-12700h/
Där finns bl.a. kompilering och Matlab. Fast vem använder Matlab 2022? NumPy är betydligt effektivare, har bättre HW-stöd (finns bl.a. CUDA-stöd som kan ge rejäl prestandaboost om man har Nvidia GPU) och är därför plattformen HW-tillverkarna primärt optimerar för idag för den här typen av laster. För Intel används dock ofta samma "back-end" för båda, deras MKL (MKL är ruggigt bra optimerad, motsvarigheten för Apple är deras Accelerate).
Angående Blender: kör man Classroom på 3.1 är redan "vanliga M1" väsentligt snabbare. MacOS har i princip varit poänglöst för den här typen av program sedan det skar sig mellan Nvidia och Apple. Men nu har Apple igen börjat fokusera på detta, Blender 3.1 är första version med "full" MacOS optimering (man använder både CPU+iGPU vilket bara har fördelar då de delar på RAM, så ingen "VRAM för litet" begränsning + GPU är långt mer effekt, den drar 4-5 W i M1).
Blender 3.1 med CPU + iGPU, M1 drar ~17 W när den renderar denna scen

Fast vem bryr sig om Blender som CPU-benchmark längre när man ser detta...

Sen såg jag detta när jag läste AnandTechs test av Alder Lakes E-kärnor

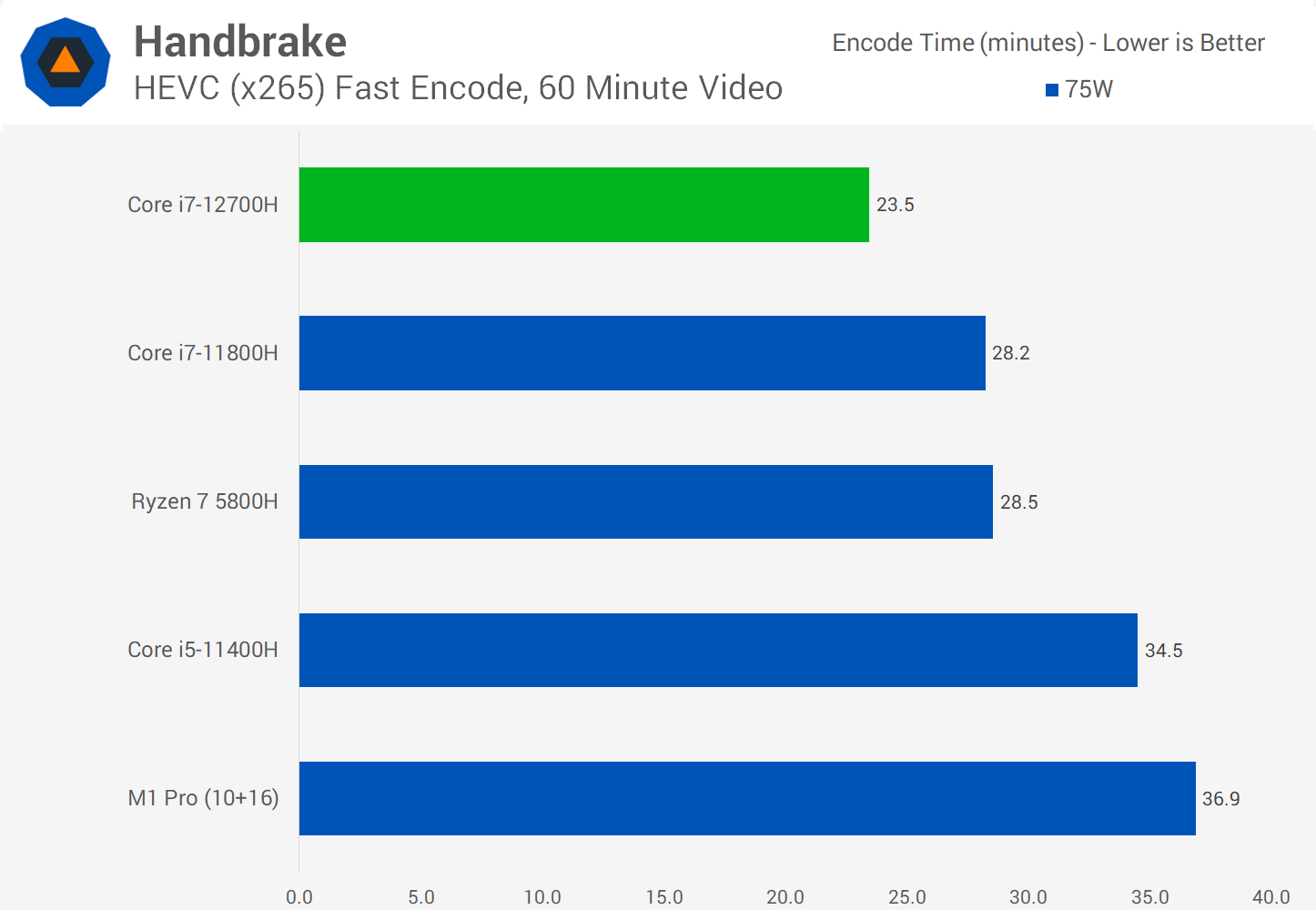
D.v.s. HVEC med Handbrake är bara delvis ett CPU-test, för E-kärnorna är inte lika snabb som P-kärnorna. Att man får detta resultat beror på att Handbrake till stor del använder GPU/Quicksync, vilket den tyvärr inte gör på M1 (men finns en lång rad videoprogram för Mac som är HW-accelererade på det sättet).
Så finns en rad rätt stora missar av Tim, han mäter inte vad han tror att han mäter!!!
Vill man verkligen jämföra CPUer finns vettiga två sätt beroende på vad man vill mäta
Titta på specifika uppgifter, välj det bästa programet (som då kan vara olika program för olika CPU/OS) för respektive system. Rätt om man vill ha svar på frågan: vilket system löser en viss uppgift bäst, vilket nog är vad de flesta vill veta egentligen
Bygg programmen från källkod med så samma kompilator som möjligt. Geekbench 5 och Spec INT/FP är väldigt bra just då de försöker undvika effekter från OS och i GB5 fall bygger man nu alla varianter med CLANG/LLVM. Man kan självklart också med fördel testa alla program man själv har tillgång till källkoden för på detta sätt. Är bästa sättet att jämföra råprestanda mellan CUPer
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer




