AMD går till berget då berget inte ville komma till AMD. Skämt åsido så försökte AMD med något nytt som kallas CMT (Clustered Multi Threading) istället för just SMT (HT) men utvecklare o.s.v. orkade eller ville inte ändra i sina program för att stödja CMT då SMT (HT) redan var så djupt rotat.
Om det var så att utvecklare hade lagt till stöd för just CMT så hade något CPU världen sett annorlunda ut idag.
CMT är bara en form av SMT.
SMT är definierat som en design där två eller flera CPU-trådar delar minst en av "fetch", "decode" och "execute".
I CMT delades "fetch" och "decode" i de två första inkarnationerna och endast "fetch" i de två senaste. Det är fortfarande SMT, en dålig variant av SMT har det visat sig, dock ändå SMT.
På hög nivå implementerar Zen och Core SMT på samma sätt, båda designerna delar alla tre stegen. Men går man in på detaljer i varje steg finns delmoment som kan vara separat per tråd, helt delat eller delat med någon form av viktning för någorlunda jämn fördelen.
Så SMT i Zen är inte identisk med SMT i Core. Faktum är att Intel bollat runt med vad som är per tråd och vad som delas mellan flera gånger, något som har haft en (liten) påverkan på enkeltrådprestanda kontra prestanda när båda trådarna används.
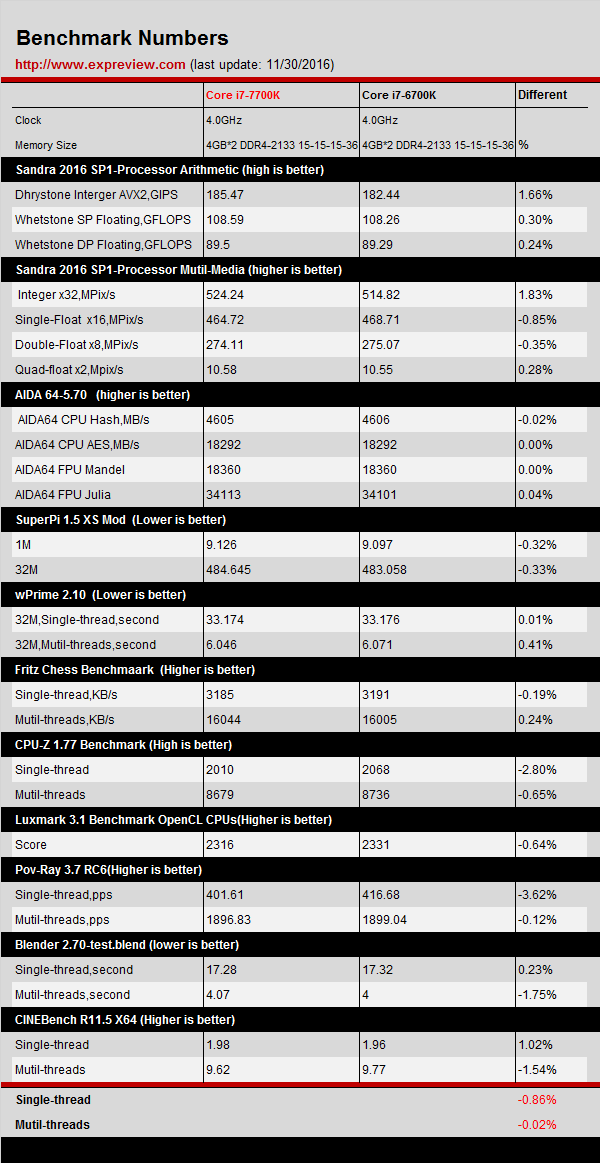
Detta är bilden AMD visat kring hur Zen delar upp saker

"micro-op queue" är t.ex. inte delad i Sandy Bridge och Skylake, men den inte är det i Ivy Bridge och Haswell (osäker på Broadwell).
En frågan: hur skulle någon kunna optimera för CMT utöver att OS scheduler känner till detta (vilket alla OS gör idag)?
Problemet med CMT var att man fick fler av nackdelarna än fördelarna från både Hyperthreading (dela även back-end) och från oberoende kärnor (inte dela något av de tre stegen). HT går faktiskt att specifikt programmera för på ett sätt som inte är en bra idé med separata kärnor. Kan inte se hur man kan göra något motsvarande för CMT, man kan ha missat något!
Min erfarenhet är tvärtom, när jag gick från en kärna till två fick jag offantligt bättre flyt, orsaken var att en process ofta kunde svälta ut den enkelkärnade CPU:n.
Ofta skiter jag i om bakgrundsjobbet går på två eller tre minuter, jag vill inte att det skall blockera datorn för mig, jag vill kunna fortsätta jobba med den.
Ja det stämmer att orsaken till detta är dålig design eller programering i programmen, men tyvärr är vi inte förskonade från sådana program, nu kan jag strunta i om en process löper amok ett tag, ansågs tydligen vara det absolut viktigaste som fanns enligt någon klant, den suger ändå bara i sig 12.5% av min CPU:kraft.
På den enkelkärnade tiden var det vanligt att WU låste datorn, En Active X skit om laddade ned, antivirus som skulle kontrollera vad som laddades ned, och uppdateringsprogrammet som ivrigt väntade på att filen skulle bli tillgänglig, lägg till pollning med allt för lite väntetid mellan anropen och katastrofen var ett faktum.
Och har aldrig pushar för CPUer med en kärna. Övergången från en CPU-kärna till två gav just de fördelar du beskriver. Man trodde därför att fler kärnor var ett vinnande koncept och tog rätt kort tid för de fyrkärninga modellerna att hitta ut både för stationära och kraftfullare bärbara.
Tyvärr gav inte övergången från två kärnor till fyra kärnor alls samma vinst för gemene man, för bärbara var det tvärtom negativt för en väldigt stor andel av fallen. Idag är bärbara med fyra kärnor därför en extremt smal nisch, betydligt smalare än för 4-5 år sedan.
SMT är vettigt för det kostar nästan ingenting. Enda konkreta siffror jag sett är att det ökade transistorbudget med mindre än 5 % på Pentium 4. Så idag lär SMT kosta max 1 % av transistorbudget på high-end modeller.
Att ha mer än en kärna är bra just för interaktiva applikationer. Orsaken är att det interaktiva jobbet då får 100 % av en kärna för att göra sina saker, resten körs "i bakgrunden".
Precis som du säger kvittar det typiskt om det man kör i bakgrunden tar 10 sekunder eller 14 sekunder. Är också sällan som det man kör i bakgrunden verkligen maxar en kärna till, Windows har trots allt haft preemptive multitaskning sedan Win95 (Linux och OSX har alltid haft det)...
Så vad jag säger är att för den stora massan som använder en dator är idag den mest optimala designen för att lösa uppgiften två kärnor med så hög prestanda som möjligt. SMT bör slängas med då det ändå inte kostar något (i alla fall inte på något likt Zen och Core).
Spel har ändå kommit så pass långt att det idag faktiskt finns en poäng med fyra kärnor. Men allt över fyra kärnor med SMT presterar i praktiken lika eller sämre. Möjligen skulle en optimal spel CPU lägga fler transistorer på cache, fyra Core-kärnor tar idag mindre än 100 mm2 och Zen-kärnor lär i alla fall inte vara större på motsvarande tillverkningsnod. Så finns ju möjlighet utrymmesmässigt att stoppa in lite annat på kislet.
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer