Kritik:
Min kritik hör inte till DLSS 2.0 i sig. Från det som jag har sett så verkar det vara en mycket bra metod, och då bör man presentera det som det utan överdrifter. Om det är bra som det är, så behöver man inte undvika att tala om felen, för ingen bryr sig om resultaten är bra. Man ska speciellt inte undvika att tala om felen om man nämnt att felen är viktiga tidigare. Kritiken handlar snarare om hur NVIDIA kommunicerat.
Då flera bildrutor används så kan saker i rörelse orsaka artefakter (i synnerhet små föremål), även om DLSS 1.9 i Control har värre problem. Alla de problemen som påvisades där är ändå inte helt borta.
Här skulle det vara bra om de påpekade att det fanns problem, men t.ex. nämnde att de var försumbara, påverkade bara lite, kan möjligtvis tränas bort i framtiden osv. Att ha en plan för hur man ska angripa ett problem är viktigt. Istället så totalignoreras det, Controls implementation nämns aldrig, även om det är den som är mest lik den nuvarande DLSS 2.0. De nämner inte vad de använde för heuristik till den, eller hur den jämförs med DLSS 2.0 i antal frames, samples och så.
När de släppte bloggen om hur de skulle gå vidare med DLSS efter Control , så sa de att ett av de stora problemen var att deras approximationsalgoritm tog bort små detaljer som rörde sig snabbt genom att sudda ut dem, medan deras AI-modell bibehöll alla detaljer.
Så nu kommer frågan: De visade upp ett stort problem med approximationsalgoritmen, nu borde DLSS 2.0 ha tagit bort detta, väl? Nej, det har det inte… (och här är ett annat exempel från mech warrior 2)
Det känns ju bra att göra ett benchmark för att visa ett problem, för att sedan inte visa samma benchmark med den nya algoritmen för att visa att problemet är löst. ¯\_(ツ)_/¯
I presentationen nämns inga nackdelar med DLSS 2.0 , ändå så är de fullt medvetna om att det har nackdelar. Den beskrivs som… perfekt. Under en del så nämner han att det finns andra heuristiker, men man får inte ens jämföra med dem för att de inte är “perfekta”. Ingenting med grafik är perfekt idag! Inte ens DLSS 2.0 är bevisligen perfekt, så varför kan dessa saker inte jämföras? Vem säger att det inte går att skapa en heuristik som levererar likartade resultat som den maskininlärda delen?
“There are many other heuristics that people have invented over the years that I haven’t really talked about, like for example motion adaptive temporal integration, aluma(?) adaptive temporal integration,and so on. But none of those heuristics are really perfect.
With DLSS 2.0 we train a neural network offline on super computers on tens of thousands of really high quality images to just learn the optimal strategy to combine samples collected over multiple frames. So instead of using handcrafted heuristics, we’re completely using a data driven approach.”
Översättning: “Vi har lagt ner mycket pengar och tid på det här så vi ser helst inte något annat komma fram som ger likartade resultat, ok?”. Det är löjligt. Det är inte förtroendeingivande att inte vilja jämföras med andra för de inte är ”perfekta” när din metod inte heller är ”perfekt”. Hade varit bättre om de konstaterat att resultaten var sämre, eller visat att de var sämre. Man kunde uttrycka sig på ett annat sätt här. (Och nej, NVIDIA är inte ensamma om att göra det här heller. Det har funnits tillfällen då AMD och Intel inte nämnt vissa saker också).
Den andra delen har att göra med att de inte har samma strategi när det kommer till 1600-serien som de har för RT. För RT sa de ”Du kan testa att se hur det ser ut med RT, även om prestandan är kass. Den är ändå bättre för RTX serien”, vilket är en helt rimlig hållning. Men när det kommer till DLSS så är det tydligen omöjligt att visa upp detta på t.ex 1600-serien, trots att det inte hade varit någon som helst skillnad mellan den och RTX korten i DLSS 1.9, förmodligen hade det även hjälpt med DLSS 2.0 om RT var aktiverat. Men då hade det ju existerat incitament för att köpa de billigare GTX korten, vilket hade varit hemskt… alltså inte för dig och mig, utan för NVIDIA. Även om det är just deras image som hade lyfts till skyarna. I DirectML hade de fått en implementation som fungerat bra på båda (även AMD och Intel) , men de hade inte kunnat uppdatera modellen som används från drivrutinerna, vilket iofs inte hade varit ett superstort problem.
Tensorkärnor är självständiga till viss mån, men inte utan bekostnad på annat. Det är ingen slump att de beskrevs som att de körs separat när de först introducerades . Vilket inte är helt sant, alla FP16 kommandon går till tensorkärnorna. Om de utnyttjas fullt ut så kan inte INT32 och FP32 användas fullt ut vad jag kan se. Om det bara är 2x FP16 så kan det köras helt parallellt. Av denna anledning har 1600-serien en dedikerad FP16 pipeline.
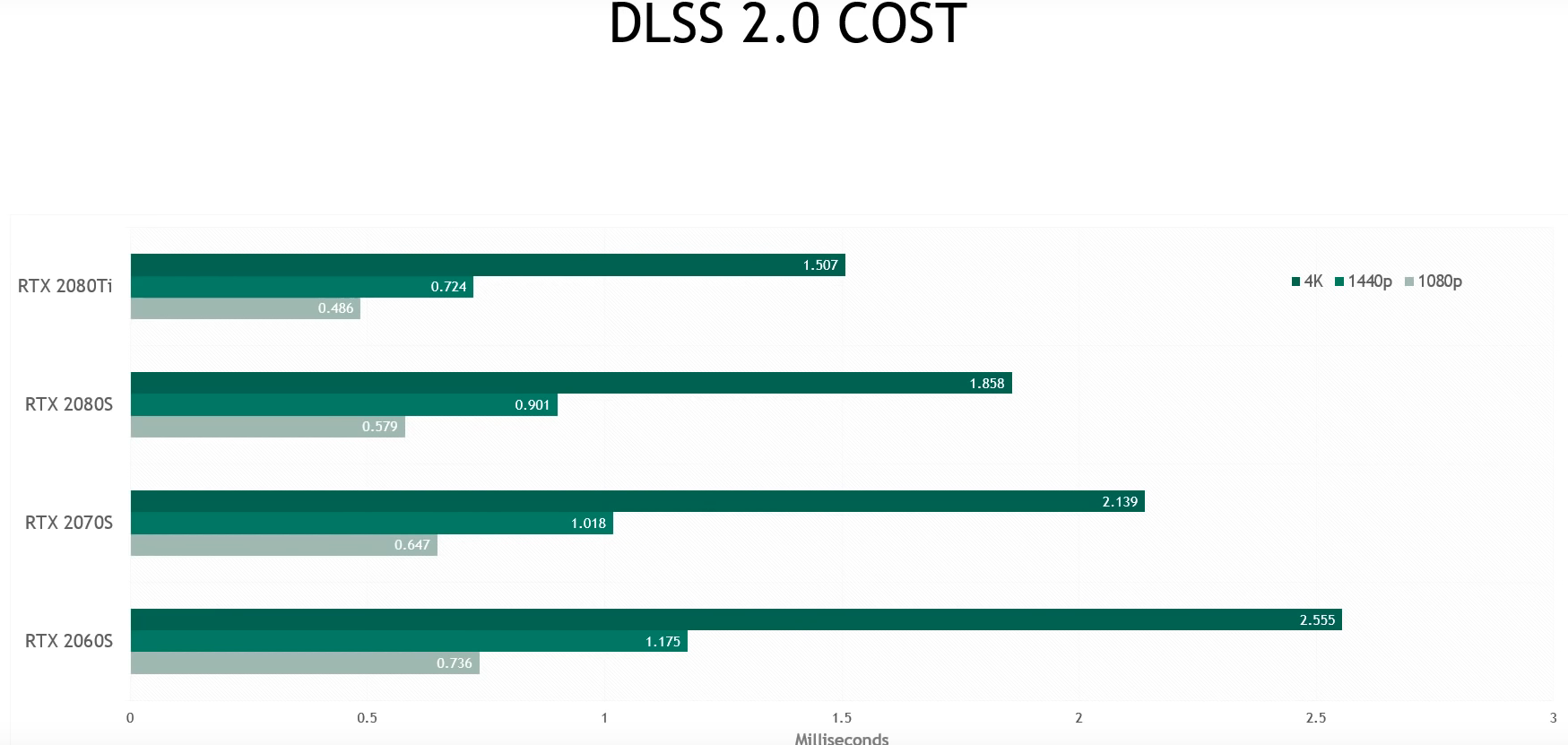
Varför är detta viktigt? Det är inte enbart tensorkärnorna som är involverade i uppskalningen, och av denna anledning så används inte all kapacitet hela tiden. Vissa delar skulle köra lika snabbt med tensorkärnor som utan tensorkärnor, medan andra skulle köras många gånger långsammare.
Här är en bild på användningen av olika enheter i Control med DLSS 1.9.
Gå ner till SM FP16+ tensor pipe throughput. Det är dessa siffror som är relevanta. I DLSS 1.9 har NVIDIA redan klarlagt att tensokärnorna inte används, och vi har en 7,9% användning på FP16 pipe. Här finns en bild med DLSS 2.0. Som går att se, så finns delar från 1.9 i 2.0 , men olika mycket (tråkigt nog hade den som tog bilden en dialogruta över vissa delar, så svårt att avgöra exakt hur mycket som de används). I synnerhet den första delen är likadan, resten skiljer sig från DLSS 1.9.
Här är de bredvid varandra och satt till samma tidsskala. Som går att se så används visserligen tensor cores upp till 75,9% ibland under väldigt korta stunder, andra gånger till ~50% under korta stunder, andra delar skulle de klarat sig lika bra utan tensor cores. Det kommer att gå mycket långsammare utan dem, ja , men inte så mycket så att det skulle vara helt värdelöst på 1600-serien. Kom ihåg att DLSS har som störst vinst när kostnaden per pixel är så hög som möjligt. Vill ni veta ett tillfälle när kostnaden per pixel är så hög som möjligt? T.ex när ray tracing körs utan RT cores.