


Asus ROG STRIX B550-F / Ryzen 5800X3D / 48 GB 3200 MHz CL14 / Asus TUF 3080 OC / WD SN850 1 TB, Kingston NV1 2 TB + NAS / Corsair RM650x V3 / Acer XB271HU (1440p165) / LG C1 55"
Mobil: Moto G200
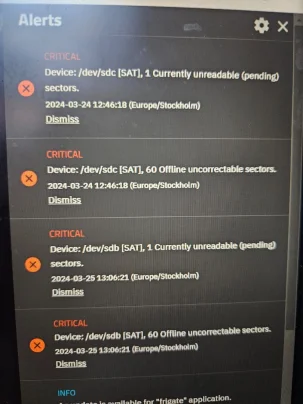
Truenas larmar om disk fel, hur allvarliga är felen?
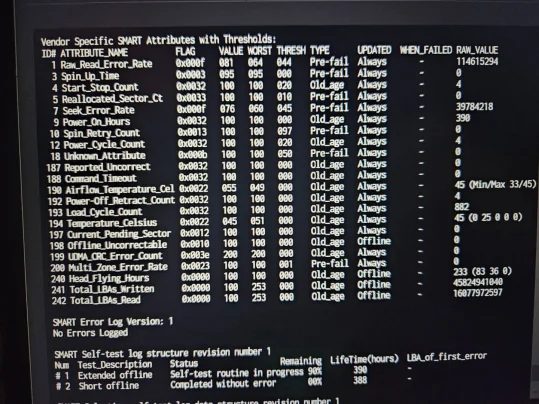
Hur ser SMART-attributerna ut för sdc?
Det ser ju inte direkt lovande ut dock med UNC (uncorrectable read error).
Den första ser väl dock frisk ut? Är du säker på att det inte är samma disk som fått olika namn (vid omstart) bara?
Visa signatur
Citera flera
Citera
=== START OF INFORMATION SECTION ===
Model Family: Toshiba MG08ACA... Enterprise Capacity HDD
Device Model: TOSHIBA MG08ACA16TE
Serial Number: 61N0A4TZF57H
LU WWN Device Id: 5 000039 af8da4a93
Firmware Version: 4002
User Capacity: 16,000,900,661,248 bytes [16.0 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database 7.3/5528
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Mar 25 20:33:07 2024 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 249) Self-test routine in progress...
90% of test remaining.
Total time to complete Offline
data collection: ( 120) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off supp ort.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: (1452) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_ FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 090 050 Pre-fail Always - 0
2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0
3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always - 7841
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 44
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline - 0
9 Power_On_Hours 0x0032 073 073 000 Old_age Always - 11174
10 Spin_Retry_Count 0x0033 100 100 030 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 44
23 Helium_Condition_Lower 0x0023 100 100 075 Pre-fail Always - 0
24 Helium_Condition_Upper 0x0023 100 100 075 Pre-fail Always - 0
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 17
193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 57
194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 36 (Min/Max 14/45)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 1
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 60
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
220 Disk_Shift 0x0002 100 100 000 Old_age Always - 35651588
222 Loaded_Hours 0x0032 073 073 000 Old_age Always - 11165
223 Load_Retry_Count 0x0032 100 100 000 Old_age Always - 0
224 Load_Friction 0x0022 100 100 000 Old_age Always - 0
226 Load-in_Time 0x0026 100 100 000 Old_age Always - 590
240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline - 0
SMART Error Log Version: 1
ATA Error Count: 64 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
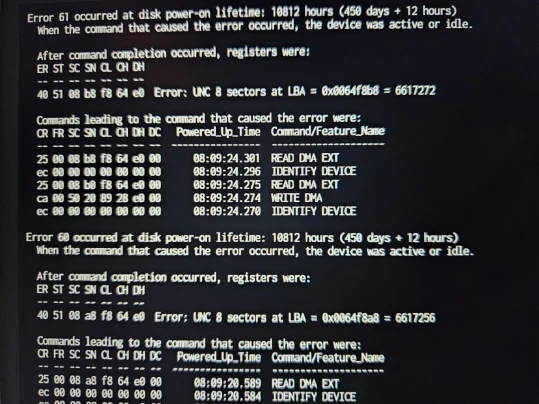
Error 64 occurred at disk power-on lifetime: 10812 hours (450 days + 12 hours)
When the command that caused the error occurred, the device was active or idle .
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 08 88 fc 64 e0 Error: UNC 8 sectors at LBA = 0x0064fc88 = 6618248
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 08 88 fc 64 e0 00 08:09:35.269 READ DMA EXT
ec 00 00 00 00 00 00 00 08:09:35.264 IDENTIFY DEVICE
25 00 08 80 fc 64 e0 00 08:09:35.252 READ DMA EXT
2f 00 01 e0 00 00 00 00 08:09:35.234 READ LOG EXT
ea 00 00 00 00 00 a0 00 08:09:35.234 FLUSH CACHE EXT
Error 63 occurred at disk power-on lifetime: 10812 hours (450 days + 12 hours)
When the command that caused the error occurred, the device was active or idle .
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 08 78 fc 64 e0 Error: UNC 8 sectors at LBA = 0x0064fc78 = 6618232
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 08 78 fc 64 e0 00 08:09:31.667 READ DMA EXT
25 00 08 70 fc 64 e0 00 08:09:31.667 READ DMA EXT
25 00 08 68 fc 64 e0 00 08:09:31.667 READ DMA EXT
25 00 08 60 fc 64 e0 00 08:09:31.667 READ DMA EXT
25 00 80 60 c3 5f e0 00 08:09:31.664 READ DMA EXT
Error 62 occurred at disk power-on lifetime: 10812 hours (450 days + 12 hours)
When the command that caused the error occurred, the device was active or idle .
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 08 90 f9 64 e0 Error: UNC 8 sectors at LBA = 0x0064f990 = 6617488
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 08 90 f9 64 e0 00 08:09:28.025 READ DMA EXT
25 00 08 88 f9 64 e0 00 08:09:28.025 READ DMA EXT
25 00 08 80 f9 64 e0 00 08:09:28.025 READ DMA EXT
25 00 08 78 f9 64 e0 00 08:09:28.025 READ DMA EXT
25 00 08 70 f9 64 e0 00 08:09:28.025 READ DMA EXT
Error 61 occurred at disk power-on lifetime: 10812 hours (450 days + 12 hours)
When the command that caused the error occurred, the device was active or idle .
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 08 b8 f8 64 e0 Error: UNC 8 sectors at LBA = 0x0064f8b8 = 6617272
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 08 b8 f8 64 e0 00 08:09:24.301 READ DMA EXT
ec 00 00 00 00 00 00 00 08:09:24.296 IDENTIFY DEVICE
25 00 08 b0 f8 64 e0 00 08:09:24.275 READ DMA EXT
ca 00 50 20 89 28 e0 00 08:09:24.274 WRITE DMA
ec 00 00 00 00 00 00 00 08:09:24.270 IDENTIFY DEVICE
Error 60 occurred at disk power-on lifetime: 10812 hours (450 days + 12 hours)
When the command that caused the error occurred, the device was active or idle .
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 08 a8 f8 64 e0 Error: UNC 8 sectors at LBA = 0x0064f8a8 = 6617256
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 08 a8 f8 64 e0 00 08:09:20.589 READ DMA EXT
ec 00 00 00 00 00 00 00 08:09:20.584 IDENTIFY DEVICE
ea 00 00 00 00 00 a0 00 08:09:20.555 FLUSH CACHE EXT
ca 00 08 90 72 45 e0 00 08:09:20.555 WRITE DMA
ea 00 00 00 00 00 a0 00 08:09:20.547 FLUSH CACHE EXT
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA _of_first_error
# 1 Short offline Completed without error 00% 11171 -
# 2 Extended offline Completed without error 00% 10844 -
# 3 Short offline Completed without error 00% 1477 -
# 4 Short offline Completed without error 00% 733 -
# 5 Short offline Completed without error 00% 31 -
# 6 Selective offline Completed without error 00% 22 -
# 7 Selective offline Completed without error 00% 21 -
# 8 Selective offline Completed without error 00% 20 -
# 9 Short offline Completed without error 00% 17 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 19090223104 19162845184 Not_testing
2 22554570752 22627192832 Not_testing
3 26018918400 26091540480 Not_testing
4 29483266048 29555888128 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
The above only provides legacy SMART information - try 'smartctl -x' for more
root@truenas[/home/admin]# smartctl -a /dev/sdc
Citera flera
Citera
=== START OF INFORMATION SECTION ===
Device Model: ST16000NM000J-2TW103
Serial Number: ZR5ELDQ0
LU WWN Device Id: 5 000c50 07445d566
Firmware Version: SN04
User Capacity: 16,000,900,661,248 bytes [16.0 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: Not in smartctl database 7.3/5528
ATA Version is: ACS-4 (minor revision not indicated)
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Mar 25 20:35:50 2024 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 249) Self-test routine in progress...
90% of test remaining.
Total time to complete Offline
data collection: ( 575) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off supp ort.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: (1529) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x70bd) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_ FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 081 064 044 Pre-fail Always - 114620670
3 Spin_Up_Time 0x0003 095 095 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 4
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 076 060 045 Pre-fail Always - 40107104
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 391
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 4
18 Unknown_Attribute 0x000b 100 100 050 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0022 055 049 000 Old_age Always - 45 (Min/Max 33/45)
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 4
193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 882
194 Temperature_Celsius 0x0022 045 051 000 Old_age Always - 45 (0 25 0 0 0)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0023 100 100 001 Pre-fail Always - 0
240 Head_Flying_Hours 0x0000 100 100 000 Old_age Offline - 234 (188 103 0)
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 45824941040
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 16077977973
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA _of_first_error
# 1 Extended offline Self-test routine in progress 90% 391 -
# 2 Short offline Completed without error 00% 388 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
The above only provides legacy SMART information - try 'smartctl -x' for more
root@truenas[/home/admin]# smartctl -a /dev/sdb
Citera flera
Citera
Skrivet av Thomas:
Hur ser SMART-attributerna ut för sdc?
Det ser ju inte direkt lovande ut dock med UNC (uncorrectable read error).
Den första ser väl dock frisk ut? Är du säker på att det inte är samma disk som fått olika namn (vid omstart) bara?
nu har jag kopiera hela smart testerna från båda. vet inte om formateringen av texterna gör det lite svår läsligt.
Så ser det ut nu, gör ett långt smart test på båda diskarna som beräknas vara klart imorgon kväll.
känns lite riskabelt att skicka iväg diskarna på garanti, tänkt om det rasar vid återställning. Om man man gör det innan man skickat iväg så har man ju ändå en disk kvar även om den inte är 100% frisk så fungerar den.
Citera flera
Citera
Exos-disken (ST16000NM000J) verkar väl frisk; inga pending/uncorrectable sectors, inga errors loggade. Den andra verkar inte må lika bra dock.
Med tanke på SMART-datan skulle jag tro att Toshiba-disken är den enda som orsakat varningarna i loggen, men att den hette sdc igår och sdb idag.
Om du kör "zpool status -P", hur ser sökvägarna ut till diskarna? Skulle gissa på att de är typ /dev/disk/by-id eller liknande och inte /dev/sdb, /dev/sdc osv? Isåfall kan de diskarna byta namn utan att ZFS bryr sig (vilket är bra, och gissningsvis vad som har hänt).
Visa signatur
Asus ROG STRIX B550-F / Ryzen 5800X3D / 48 GB 3200 MHz CL14 / Asus TUF 3080 OC / WD SN850 1 TB, Kingston NV1 2 TB + NAS / Corsair RM650x V3 / Acer XB271HU (1440p165) / LG C1 55"
Mobil: Moto G200
Citera flera
Citera
(2)
Skrivet av Thomas:
Exos-disken (ST16000NM000J) verkar väl frisk; inga pending/uncorrectable sectors, inga errors loggade. Den andra verkar inte må lika bra dock.
Med tanke på SMART-datan skulle jag tro att Toshiba-disken är den enda som orsakat varningarna i loggen, men att den hette sdc igår och sdb idag.
Om du kör "zpool status -P", hur ser sökvägarna ut till diskarna? Skulle gissa på att de är typ /dev/disk/by-id eller liknande och inte /dev/sdb, /dev/sdc osv? Isåfall kan de diskarna byta namn utan att ZFS bryr sig (vilket är bra, och gissningsvis vad som har hänt).
Ja det verkar som det du skriver stämmer att den sorterar diskarna så.
mirror-0 ONLINE 0 0 0
/dev/disk/by-partuuid/8a990512-5be9-4975-9dab-a6858c8c4890 ONLINE 0 0 0
/dev/disk/by-partuuid/a8f24523-254d-4a04-a790-7a4cb0368cae ONLINE 0 0 0
Då blev läget bättre, men skall kontakta butiken om toshiba disken, den är ju bara 415 dagar eller vad det stod och är 5 år garanti.
Men då skall jag bara ta och fundera på om man skall skaffa en ny disk i väntan på garanti. En hotspare är ju inte fel att ha , men de kostar ju en slant, har funderat på en sån där renoverad disk från amazon för att ha som hotspare.
Nu skall jag också ta och märka om diskslädarna med serie nr i stället, för det verkar ju inte vara ett rätt längre då jag döpte dem efter namnen.
Citera flera
Citera

Skrivet av jope84:
Hej min server spottar ur sig lite varningar.
Hur allvarliga är felen? Vågar man skicka in diskarna på garanti och vänta in ersättnings disken eller skall man köpa ny och ersätta innan ?
Kör zfs mirror stripe (RAID-10).
Ena disken larmade i min synology, men efter långt smart test så godkände den det, stoppade in den i nya servern och fick nu ett nytt fel.
Ett nytt fel är helt klart tillräckligt för att byta ut den.
Kör du från en Linux Live-ISO så kan programmet diskar (gnome-disks från terminalen) testa och visa SMART-värden.
Visa signatur
Server: Fractal design Define 7 XL | AMD Ryzen 7 5800X 8/16 | ASUS ROG CROSSHAIR VIII DARK HERO | 64GB Corsair @ 3000MHz | ASUS Radeon RX 460 2GB | Samsung 960 PRO 512 GB M.2 | 2x 2TB Samsung 850 PRO SSD | 6x Seagate Ironwolf Pro 10TB
WS: Phantex Entoo Elite | AMD Ryzen Threadripper 1950X 16/32 | ASUS Zenith extreme | 128GB G.Skill @ 2400MHz | ASUS Radeon HD7970 | 3x 2TB Samsung 960PRO M.2 | 6x Seagate Ironwolf Pro 10 TB
NEC PA301W 30" @ 2560x1600 | Linux Mint 21.3 Cinnamon
Citera flera
Citera

Ta ur Toshibadisken om du kan och sätt i en USB-docka och göre en zerofill på denna med typiskt "dd if=/dev/zero of=/dev/sdx bs=1024k status=progress" - sdx är här någon av /dev/sda, /dev/sdb etc. och letas fram med lsblk precis innan man kör kommandot - gör övningen på _rätt_ disk!!!
Som nämnt kan diskarnas ordningsföljd i avseende sda, sdb, sdc etc. flyttas om för var boot/start då det är något som numreras upp av BIOS/PCIe-systemets POST efter ordningen när enheterna signalerar sig klara - och ordningsföljden kan alltså bli olika per start.
---
Slutar post 198 att räkna upp efter detta och post 197 blivit 0 igen och när den är resilvrad i din NAS igen så är problemet löst och disken håller förmodligen många år till.
En zerofill av en krånglande snurrdisk kan göra mer nytta än någon av diskens egna självtester då när den skriver kontinuerligt med data så skriver det över det gamla datan utan att försöka tolka det som var innan och då får man nya och fräscha sektorer med hög signal över brus skrivna på diskytan.
Att en sektor kan vara vek beror oftast inte på att magnetkornen på ytan skulle ha tappat någon magnetism över tiden utan snarare att skrivhuvudet var lite off track och vinglade i sin tänkta spår av tex. mekanisk stöt eller vibration när datat skrevs och vid senare läsning så är en del av magnetspåret lite på sidan av spåret den läses och signalstyrkan lägre just där läshuvudet läser med kanske bara halva spårbredden kvar av det skrivna datat innan.
Det är ordentligt avancerad servosystem för att flytta läshuvudet mekanisk inom mindre än 10 nm rätt centrerat i spårets bredd (gissningsvis mindre än 70 nm bredd idag och ligger kant i kant med spåren brevid) och det fins situationer där det inte hinner att centrera spåret precis rätt i alla lägen pga. vibrationer och stötar mm. samtidigt under tex. skrivning
Citera flera
Citera
Hårdvara
- Igår Corsair Platform 6: För dig som inte nöjer dig med Ikea-skrivbord 11
- Igår Rykte: Switch 2 släpps i höst – OLED-variant dröjer 35
- Igår Iphones marknadsandel faller i USA 43
- 25 / 4 Airtec Pro Type1 – batteridrivet alternativ till tryckluft på burk 92
- 25 / 4 Nu stiger hårddiskpriserna med uppemot 10 procent 23
Mjukvara
Datorkomponenter
Ljud, bild och kommunikation
- Krönika: "Early access" är utstuderad girighet33
- RX 7900XT/XTX Owners Club860
- Formel 1-tråden8891
- Övriga Fynd – Diskussionstråd1263
- Problem med GPU0
- Hjälp med nyinköpt nätagg: BeQuiet Pure Power 12M. Har jag köpt fel?2
- Sur, Ledsen, Galen?! Skriv av er här!21523
- Mekaniska tangentbord – Allmän diskussion6999
- Guide: Sätta upp en RAM-disk för Nvidia Instant Replay (f.d. Shadowplay)75
- Luft/vattenvärmepump-tråden2
- Säljes Säljer helt NYTT Vengeance 32GB RGB DDR5 6000Mhz
- Säljes Bärbar ASUS 4800H, RTX 2060, 512 GB SSD, 16 GB RAM
- Säljes Helt NYTT Gigabyte Z790 Aorus Elite AX.
- Säljes Valve Index VR Kit
- Köpes Playstation 4 Pro
- Säljes 2x Xeon 5365 3.0GHz + 8gb DDR2 667MHz + Nvidia GT7300 GPU
- Säljes Lian Li O11 Dynamic XL svart samt 360mm radiatorer
- Säljes Xbox Elite Wireless Series 2 handkontroll
- Bytes Ny RM750x mot SFX
- Säljes RX 6800 XT Asus Strix LC OC och Samsung Odyssey G7 27"
- Krönika: "Early access" är utstuderad girighet33
- Övergivet skadeprogram infekterar miljontals maskiner11
- Helgsnack: Är all reklam till ondo?67
- Microsoft släpper källkoden till MS‑DOS 4.0016
- Ny caps lock-symbol i Windows förbryllar HP-användare20
- Corsair Platform 6: För dig som inte nöjer dig med Ikea-skrivbord11
- Rykte: Switch 2 släpps i höst – OLED-variant dröjer35
- NetonNet varnar om läckta kunduppgifter23
- Premiär på SweClockers! Månadens drop med gamingskärm hos Elgiganten74
- IT-bolag: Teknikstrul är största tidsboven idag42
