


[ Corsair Obsidian 650D ][ Corsair AX850 ][ Intel Core i7 2600k ][ Noctua NH-U12P-SE2 ][ Asus P8Z68V-Pro ]
[ 16Gb G-Skill RipJaws Gaming ][ Crucial M4 128gb SSD ][ Seagate Barracuda Green 2TB HDD ]
[ KFA2 Geforce GTX570 1280MB ][ Samsung S24A350 Monitor ][ Win7 SP1 Enterprise 64-bit ]
Crucial lanserar M4 – ny SSD i 25 nanometer
Skrivet av echo:
Bara för att du kan kombinera skrivningen med en TRIMning har du ju inte tjänat något på det resonemanget. TRIMningen är ju återigen inget som räknas med i det teoretiska resonemanget och därmed så har du bara minimerat ytterligare förluster utöver det jag kommenterade...
Trim utförs inte nödvändigtvis direkt, vettiga diskar sparar informationen med väntar ett tag med själva rensningen för att kunna minimera antalet p/e cykler. Om disken sköter det bra så slipper man många onödiga p/e cykler då halvtomma block samlas ihop till ett mindre antal fulla och de som då blir helt tomma raderas. Du har då ett antal block som inte behövs raderas innan man kan skriva till dom och du har då minskat write amplifikation drastiskt. Som sagt så rekommenderar jag dig att titta på sidan jag länkade till, Anand får anses vara en av de mer trovärdiga källorna när det gäller detta så jag har ingen anledning att misstro den information han lämnar om sin egen 120gb vertex 2 som hade en vrite amplification på 0.6. Självklart så tjänar man mycket på komprimeringen, men jag har svårt att tro att man klarar av att komprimera genomsnittlig data mer än ca 2:1 och då har man en write amplification på ca 1.2 vilket även det är mycket lågt.
Det finns alltså i nuläget ingen anledning att tro att de 72tb som anges i artikeln är en fantasisiffra, om du har påtaglig information om motsatsen så får du gärna dela med dig av den, än så länge så faller dina påståenden in i kategorin: "Jag tycker att det är så här!" snarare än något som faktiskt verkar vara baserat på reell information.
Citera flera
Citera
Skrivet av Frispel:
Trim utförs inte nödvändigtvis direkt, vettiga diskar sparar informationen med väntar ett tag med själva rensningen för att kunna minimera antalet p/e cykler. Om disken sköter det bra så slipper man många onödiga p/e cykler då halvtomma block samlas ihop till ett mindre antal fulla och de som då blir helt tomma raderas. Du har då ett antal block som inte behövs raderas innan man kan skriva till dom och du har då minskat write amplifikation drastiskt. Som sagt så rekommenderar jag dig att titta på sidan jag länkade till, Anand får anses vara en av de mer trovärdiga källorna när det gäller detta så jag har ingen anledning att misstro den information han lämnar om sin egen 120gb vertex 2 som hade en vrite amplification på 0.6. Självklart så tjänar man mycket på komprimeringen, men jag har svårt att tro att man klarar av att komprimera genomsnittlig data mer än ca 2:1 och då har man en write amplification på ca 1.2 vilket även det är mycket lågt.
Det finns alltså i nuläget ingen anledning att tro att de 72tb som anges i artikeln är en fantasisiffra, om du har påtaglig information om motsatsen så får du gärna dela med dig av den, än så länge så faller dina påståenden in i kategorin: "Jag tycker att det är så här!" snarare än något som faktiskt verkar vara baserat på reell information.
Varför tjatar du om TRIM hela tiden när jag inte ens anklagat TRIM vad gäller nand-slitaget? Känns som du har missförstått något...
Sen har du gjort det väldigt bekvämt för dig genom att undvika att nämna något om wear-level-algoritmerna.
Senast redigerat
Citera flera
Citera
Skrivet av echo:
Varför tjatar du om TRIM hela tiden när jag inte ens anklagat TRIM vad gäller nand-slitaget? Känns som du har missförstått något...
Sen har du gjort det väldigt bekvämt för dig genom att undvika att nämna något om wear-level-algoritmerna.
Mitt tidigare inlägg var en respons på ditt inlägg:
Skrivet av echo:
Bara för att du kan kombinera skrivningen med en TRIMning har du ju inte tjänat något på det resonemanget. TRIMningen är ju återigen inget som räknas med i det teoretiska resonemanget och därmed så har du bara minimerat ytterligare förluster utöver det jag kommenterade...
Men vi kan lämna ämnet trim åt sidan just, verkar inte vara helt relevant för fortsatt diskussion...
Angående wear leveling så tar bilden längst upp på anandtechs artikel upp wear leveling:
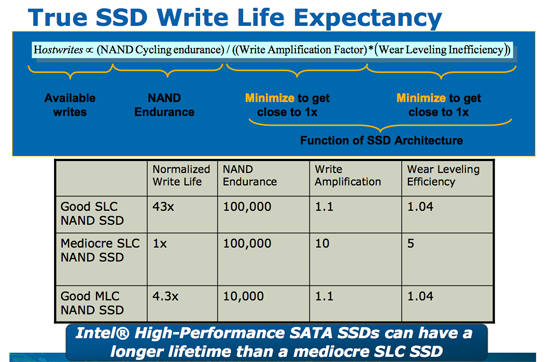
och även jag kommenterade det ett antal ggr i tidigare inlägg, bara att läsa citatet nedan
Skrivet av Frispel:
Edit:
Lite räkneövningar visar att 72tb innebär ca 550 skrivningar per cell på en 128gb disk utan write amplification och med perfekt wear leveling. Om man har dålig wear leveling (x2) och relativt hög write amplification (x2,5) så kommer det fortfarande att få in dessa 72tb innan cellerna tar slut. Utöver det så finns det reservutrymme för att kunna ersätta celler som tar slut i förtid eller slits ut tidigare pga av eventuella misslyckanden med wear leveling. De flesta moderna ssd:er klarar så pass mycket skrivningar att de högst troligen kommer att dö av andra orsaker än att cellerna slits ut.
En modern disk klarar också av att flytta runt data så att en disk som är nästan full med statisk data har möjlighet att vid behov cirkulera informationen så att det inte bara är de oanvända cellerna som slits.
Som sagt tidigare, har du information som motsäger anandtechs påståenden så dela gärna med dig av den, annars så är det fortfarande dina personliga åsikter du delar med dig av och än så länge så är det en påtaglig brist på information om vad grunden är till dessa åsikter är. Vad baserar du egentligen din uppfattning på?
Citera flera
Citera
Skrivet av Frispel:
Mitt tidigare inlägg var en respons på ditt inlägg
Ja och det skrev jag ju bara för att du tog upp TRIM till att början med (som svar till mig?)...
Skrivet av Frispel:
Angående wear leveling så tar bilden längst upp på anandtechs artikel upp wear leveling: http://images.anandtech.com/reviews/storage/Intel/SSDlaunch/c...
och även jag kommenterade det ett antal ggr i tidigare inlägg, bara att läsa citatet nedan
En modern disk klarar också av att flytta runt data så att en disk som är nästan full med statisk data har möjlighet att vid behov cirkulera informationen så att det inte bara är de oanvända cellerna som slits.
Varken du eller anandtech har ens berört effektiviteten på wear-level-algoritmerna (dvs. det som är intressant). Har du någon källa på att din wear-level-algoritm i ditt exempel skulle vara dålig?
Skrivet av Frispel:
Som sagt tidigare, har du information som motsäger anandtechs påståenden så dela gärna med dig av den, annars så är det fortfarande dina personliga åsikter du delar med dig av och än så länge så är det en påtaglig brist på information om vad grunden är till dessa åsikter är. Vad baserar du egentligen din uppfattning på?
Jag säger inte emot anandtechs påståenden ö.h.t.. Anandtech förutsätter i alla sina exempler och i alla artiklar jag läst (även det du länkar) att wear-level-algoritmen är perfekt vilket gör i princip alla deras resonemang om slitage rätt värdelösa. Jag grundar mina påståenden på avsaknaden av information, hur wear-level-algoritmerna fungerar och presterar är företagshemlighteter.
Vi har alltså två faktorer som vi inte får veta någonting om och som anses fungera perfekt (helt orimligt).
Om vi förenklar bilden lite och utgår från nyheten där det står att deras 512 GB disk klarar av att skriva 72TB.
72 TB / 512 GB = 144, dom räknar alltså med att man bara kan skriva över disken 144 gånger. Sätter man in dessa siffror i formeln som du länkar så får du (x = write amplification factor, y = wear leveling inefficiency):
(512 GB * 144) / (x * y) (vilket är < 72 TB i alla fall)
Kan du svara mig vad svaret blir? Nog för att matte inte är mitt favoritämne men jag tror nog de flesta har svårt att få ut något ur det där när två av faktorerna är okända...
Detta varierar givetvis kraftigt mellan diskar (men specifikationen är densamma oavsett hur bra eller dålig disken är).
Citera flera
Citera
Skrivet av echo:
Ja och det skrev jag ju bara för att du tog upp TRIM till att början med (som svar till mig?)...
Varken du eller anandtech har ens berört effektiviteten på wear-level-algoritmerna (dvs. det som är intressant). Har du någon källa på att din wear-level-algoritm i ditt exempel skulle vara dålig?
Jag säger inte emot anandtechs påståenden ö.h.t.. Anandtech förutsätter i alla sina exempler och i alla artiklar jag läst (även det du länkar) att wear-level-algoritmen är perfekt vilket gör i princip alla deras resonemang om slitage rätt värdelösa. Jag grundar mina påståenden på avsaknaden av information, hur wear-level-algoritmerna fungerar och presterar är företagshemlighteter.
Vi har alltså två faktorer som vi inte får veta någonting om och som anses fungera perfekt (helt orimligt).
Om vi förenklar bilden lite och utgår från nyheten där det står att deras 512 GB disk klarar av att skriva 72TB.
72 TB / 512 GB = 144, dom räknar alltså med att man bara kan skriva över disken 144 gånger. Sätter man in dessa siffror i formeln som du länkar så får du (x = write amplification factor, y = wear leveling inefficiency):
(512 GB * 144) / (x * y) (vilket är < 72 TB i alla fall)
Kan du svara mig vad svaret blir? Nog för att matte inte är mitt favoritämne men jag tror nog de flesta har svårt att få ut något ur det där när två av faktorerna är okända...
Detta varierar givetvis kraftigt mellan diskar (men specifikationen är densamma oavsett hur bra eller dålig disken är).
Tja, på bilden som jag tog med så skriver Anand att wear leveling på en bra disk hamnar på ca 1.04 mendans den hamnar på ca 5 på en medioker dito. Mata in sifforna i formeln han ger så ser du var man hamnar. Återigen, har du information som påvisar något annat så dela gärna med dig av den. Det jag gick igång på var dina påståenden tidigare:
Skrivet av echo:
Lycka till att hitta en metric som är mer missvisande än det där.
Genialiskt drag av SSD-tillverkarna att minska fokuset på pålitlighet.
Är det inte tvärtom? Precis som Anand så påpekar dom att disken klarar mer skrivningar än de flesta kommer att göra och att begränsningen i cellernas p/e cykler inte är något en normal användare behöver oroa sig för? Har än så länge inte hört talas om någon som haft en ssd som tagit slut pga att cellerna tar slut och därmed blivit "read only".
Skrivet av echo:
Det bygger på helt orimliga antaganden, nämligen att att wear-level-teknikerna är perfekta och att all data som skrivs matchar blockstorlekarna på SSDn.
Finns ingen som helst verklighetsanknytning i dessa antaganden.
Wear leveling behöver inte vara perfekt för att hamna på dessa siffror som jag har skrivt tidigare. Blockstorleken är inte heller speciellt intressant om man har en intelligent kontroller som tex kan samla ihop halvtomma block i ett fåtal fulla och resten tomma.
Skrivet av echo:
Jusst därför att en skrivning på t.ex. 4 kB kommer innebära att ett helt block ändras (raderas och skrivs om) så betyder det att ur flashminnets perspektiv så har man skrivit ett helt block (128 kB ?) medans man i deras teoretiska resonemang bara har förbrukat 4 kB.
(eller hur stort är ett block nuförtin? X25-m kör väl 128 kB om jag inte minns fel men fått intrycket av att nyare diskar kör med större, hursom så är det relativt stort)
Om inte annat så skulle det märkas på skrivprestandan so skulle sjunka drastiskt när alla cellerna väl skrivits till en gång. Ungefär som på ett par usb-minnen jag har som skriver små filer hysteriskt långsamt nu när alla celler väl skrivts till en gång. Det var bla det som gjorde att tidiga ssd:er fick problem med små skrivningar så att systemet läste sig i någon sekund då och då när disken var tvungen att göra hela den processen du beskriver. Det är som du kanske märkt(?) inte längre ett problem med moderna diskar.
Skrivet av echo:
Visst är MTBF en rätt värdelös siffra i sin ensamhet (särskilt för oss konsumenter) men det blir inte bättre att ersätta den med något annat lika värdelöst. MTBF har åtminstone många lärt sig att ignorera.
De borde inte publiceras ö.h.t. av swec. och andra siter. Nu tillängnas ett helt stycke i nyheten till att uppmärksamma läsarna på något som bara existerar för att vilseleda konsumenterna (som sagt, genialiskt drag av SSD-tillverkarna).
Tja, se ovan...
Det du har skrivt tidigare tyder på att du tycker att det verkar otroligt pga att du faktiskt inte vet hur det fungerar? Är det inte bra att ha lite faktisk grund bakom så kategoriska påståenden som du slängt ur dig i denna tråden? Jag ber dig återigen dela med dig av vad du faktiskt vet(?) om detta snarare än vad du tror eller tycker...
Citera flera
Citera
Skrivet av Frispel:
Tja, på bilden som jag tog med så skriver Anand att wear leveling på en bra disk hamnar på ca 1.04 mendans den hamnar på ca 5 på en medioker dito. Mata in sifforna i formeln han ger så ser du var man hamnar. Återigen, har du information som påvisar något annat så dela gärna med dig av den. Det jag gick igång på var dina påståenden tidigare:
Ah det missade jag, men varifrån kommer dom siffrorna?
Skrivet av Frispel:
Är det inte tvärtom? Precis som Anand så påpekar dom att disken klarar mer skrivningar än de flesta kommer att göra och att begränsningen i cellernas p/e cykler inte är något en normal användare behöver oroa sig för? Har än så länge inte hört talas om någon som haft en ssd som tagit slut pga att cellerna tar slut och därmed blivit "read only".
Jag har heller inte påstått något annat. Varför lägger du saker i min mun hela tiden?
Att SSD-tillverkarna har gjort detta för att minska fokuset på pålitlighet är rätt uppenbart men hurvida pålitlighetsdebatten är befogad eller ej har jag inte sagt något om. Att jag kritiserar ett mått på pålitlighet är inte ekvivalent med att jag påstår att SSDs är opålitliga.
Skrivet av Frispel:
Wear leveling behöver inte vara perfekt för att hamna på dessa siffror som jag har skrivt tidigare. Blockstorleken är inte heller speciellt intressant om man har en intelligent kontroller som tex kan samla ihop halvtomma block i ett fåtal fulla och resten tomma.
Blockstorleken är intressant i många aspekter men bara för att nämna en sak så kan vi ta ditt exempel. Utgå från två block som är fulla till en tredjedel och så ska du skriva låt säga en fjärdedel till. Den smarta kontrollern läser in dessa två block, kombinerar det med den nya datan som ska skrivas och skriver allt i ett nytt block.
Vi har nu ett närapå fullt block med data och de två tidigare blocken kan TRIMmas bort när kontrollern känner för det. Vad vi har tjänat på detta är att vi frigjort två block samtidigt som vi skrev vår nya data, detta har vi dock ingen glädje utav ur slitagesynpunkt (vi har fortfarande skrivit ett block trotts att vi bara behövde skriva en fjärdedel av det)...
Bara för att vi har två tomma block betyder inte på något magiskt vis att slitaget minskar, dessa block måste raderas innan de kan användas till något vettigt.
Skrivet av Frispel:
Om inte annat så skulle det märkas på skrivprestandan so skulle sjunka drastiskt när alla cellerna väl skrivits till en gång. Ungefär som på ett par usb-minnen jag har som skriver små filer hysteriskt långsamt nu när alla celler väl skrivts till en gång. Det var bla det som gjorde att tidiga ssd:er fick problem med små skrivningar så att systemet läste sig i någon sekund då och då när disken var tvungen att göra hela den processen du beskriver. Det är som du kanske märkt(?) inte längre ett problem med moderna diskar.
Men va? Relevans?
Tänk igenom scenariot.
Jag skriver 4 kB data till en SSD. Detta måste givetvis lagras någonstans, på något utav diskens block. Eftersom en SSD inte kan ändra data i ett block utan att skriva om hela blocket så spelar det ingen roll om alla celler används eller om 99% av disken är tom. För att lagra mina 4 kB så kommer SSDn vara tvungen att skriva till minst ett block, det går inte att komma ifrån. För att detta block ska kunna användas till något annat igen så måste hela blocket raderas, alltså motsvarar slitaget på disken storleken på ett block. Det spelar ingen roll om disken passar på att flytta runt data eller omorganiserar data i samma svep, det är ofrånkomligt att det skrivs i ett block. Det spelar heller ingen roll om disken har TRIMmat bort en massa ledigt utrymme och därmed redan har färdiga block att skriva i.
Men sen kan SSDn givetvis kombinera min skrivning med en annan som råkade ske ungefär samtidigt men du kan aldrig komma ifrån att varje skrivning som görs förbrukar åtminstone ett block.
Alltså, jag skriver x kB data och SSDn skriver detta i y block.
Jag hoppas du är med på det?
Då är bara frågan varifrån detta block kommer. Nej det är inte säkert att man måste radera ett block jusst precis innan man skriver till ett (här har vi poängen med TRIM) men för att ett block ska kunna användas måste det tidigare ha raderats (ignorerar nu när disken är ny och alla block redan är nollade). Alla skrivningar har förekommit av att blocket raderas. Det spelar ingen roll (för slitagets skull) om blocket måste raderas precis innan skrivningen eller om blocket raderades förra veckan tack vare TRIM. Slitaget är fortfarande konstant.
Den processen jag beskriver är alltså det som händer vid varje skrivning på varje SSD (förutom i början när disken redan är blank), det är lite lustigt att du gång på gång anklagar mig för att inte ha koll när du själv verkar duktigt förvirrad och har svårt för att skriva något av relevans.
Skrivet av Frispel:
Det du har skrivt tidigare tyder på att du tycker att det verkar otroligt pga att du faktiskt inte vet hur det fungerar? Är det inte bra att ha lite faktisk grund bakom så kategoriska påståenden som du slängt ur dig i denna tråden? Jag ber dig återigen dela med dig av vad du faktiskt vet(?) om detta snarare än vad du tror eller tycker...
Det räcker med sunt förnuft.
diskens pålitlighet = (minnets pålitlighet) / x , där x > 1 och anses vara en företagshemlighet
Tillverkarna stoltserar med minnets pålitlighet men konsumenterna är givetvis intresserade av diskens pålitlighet (med pålitlighet menar jag bara diskens sårbarhet för slitage (eftersom det är det som jag kommenterat)).
Vill du köpa ett USB-minne av mig?
Det rymmer (1000 TB / x) där x är en positiv hemlig konstant, det kostar 100 kr, låter det som en bra deal?
Citera flera
Citera
Skrivet av echo:
Men va? Relevans?
Tänk igenom scenariot.
Jag skriver 4 kB data till en SSD. Detta måste givetvis lagras någonstans, på något utav diskens block. Eftersom en SSD inte kan ändra data i ett block utan att skriva om hela blocket så spelar det ingen roll om alla celler används eller om 99% av disken är tom. För att lagra mina 4 kB så kommer SSDn vara tvungen att skriva till minst ett block, det går inte att komma ifrån. För att detta block ska kunna användas till något annat igen så måste hela blocket raderas, alltså motsvarar slitaget på disken storleken på ett block. Det spelar ingen roll om disken passar på att flytta runt data eller omorganiserar data i samma svep, det är ofrånkomligt att det skrivs i ett block. Det spelar heller ingen roll om disken har TRIMmat bort en massa ledigt utrymme och därmed redan har färdiga block att skriva i.
Men sen kan SSDn givetvis kombinera min skrivning med en annan som råkade ske ungefär samtidigt men du kan aldrig komma ifrån att varje skrivning som görs förbrukar åtminstone ett block.
Jag hoppas att du förstått att det är raderingen som sliter på cellen. Ett raderat och tomt eller delvis tomt block kan lägga till data på de delar som ännu är oprogrammerade, det är först när hela blocket fyllts av data som man behöver radera det för att kunna skriva igen och därmed använda en p/e cykel. Varje skrivning innebär således inte automatiskt att ett helt block måste raderas som du verkar tro?
Skrivet av echo:
Alltså, jag skriver x kB data och SSDn skriver detta i y block.
Jag hoppas du är med på det?
Då är bara frågan varifrån detta block kommer. Nej det är inte säkert att man måste radera ett block jusst precis innan man skriver till ett (här har vi poängen med TRIM) men för att ett block ska kunna användas måste det tidigare ha raderats (ignorerar nu när disken är ny och alla block redan är nollade). Alla skrivningar har förekommit av att blocket raderas. Det spelar ingen roll (för slitagets skull) om blocket måste raderas precis innan skrivningen eller om blocket raderades förra veckan tack vare TRIM. Slitaget är fortfarande konstant.
Den processen jag beskriver är alltså det som händer vid varje skrivning på varje SSD (förutom i början när disken redan är blank), det är lite lustigt att du gång på gång anklagar mig för att inte ha koll när du själv verkar duktigt förvirrad och har svårt för att skriva något av relevans.
Det du pratar om här är write amplification och är definitivt något som existerar, men Anand visar i sin artikel att den till och med hamnar på under 1 med en sandforce disk tack vare komprimeringen (0.6). Kan tänka mig att kontrollers som inte komprimerar hamnar på som mest dubbla till tredubbla den siffran (1.2-1.8), mer än så brukar det inte gå att i komprimera genomsnittlig data.
Anledningen till att dom tar med dessa 72TB i marknadsföringen är så klart för att folk ska veta att disken inte kommer att dö i förtid pga utslitna nandceller vilket är en ofta förekommande fråga även här på forumet, man måste skriva kopiösa mängder data för att en vettig ssd ska dö i förtid pga just den orsaken.
Citera flera
Citera
Skrivet av Frispel:
Jag hoppas att du förstått att det är raderingen som sliter på cellen. Ett raderat och tomt eller delvis tomt block kan lägga till data på de delar som ännu är oprogrammerade, det är först när hela blocket fyllts av data som man behöver radera det för att kunna skriva igen och därmed använda en p/e cykel. Varje skrivning innebär således inte automatiskt att ett helt block måste raderas som du verkar tro?
Sant, det har jag missförstått (inte att det är raderingen som sliter utan att man kan appenda). Fasst det innebär ju dessutom att det sliter mer att slå ihop flera dåligt utnyttjade block till ett.
Skrivet av Frispel:
Anledningen till att dom tar med dessa 72TB i marknadsföringen är så klart för att folk ska veta att disken inte kommer att dö i förtid pga utslitna nandceller vilket är en ofta förekommande fråga även här på forumet
Givetvis, och det inger inte mycket förtroende eller försäkran när den siffran dom anger inte går att uppnå i verkligheten - det är ju det jag har klagat på.
Skrivet av Frispel:
... man måste skriva kopiösa mängder data för att en vettig ssd ska dö i förtid pga just den orsaken.
Och det är det som du bara har tillverkarens ord på.
Senast redigerat
Citera flera
Citera
Skrivet av echo:
Sant, det har jag missförstått (inte att det är raderingen som sliter utan att man kan appenda). Fasst det innebär ju dessutom att det sliter mer att slå ihop flera dåligt utnyttjade block till ett.
.
Nja, om man ska skriva till ett fyllt block där bara delar av datan används (ett delvit tomt men "smutsigt" block) så blir annars proceduren för det blocket:
läs den data som redan finns där -> radera -> skriv den tidigare datan plus den nya.
Då kan man lika gärna slå ihop ett antal halvtomma men "smutsiga" block i ett färre antal fulla och ett antal helt tomma så blir det färre raderingar i framtiden.
Skrivet av echo:
Givetvis, och det inger inte mycket förtroende eller försäkran när den siffran dom anger inte går att uppnå i verkligheten - det är ju det jag har klagat på.
.
Poängen är återigen att folk inte ska oroa sig för att ssd:n ska dö av utslitna nandceller, den kommer antagligen att dö av liknande saker som andra komponenter dör av. Det är som sagt många som hört att en ssd tål ett begränsat antal skrivningar och då i onödan oroar sig för att deras nya fina ssd ska dö av det. Om siffran inte går att uppnå i verkligheten så beror det nog i så fall huvudsakligen på att ingen/väldigt få skriver så mycket till sin disk
Skrivet av echo:
Och det är det som du bara har tillverkarens ord på.
Baserat på det exempel som Anand tar upp så har jag ingen anledning att tro att det är tilltaget i överkant, om något så tror jag att det kan ses som ett minsta värda med god marginal uppåt beroende på hur man använder disken. Men det är antagligen irrelevant då jag har svårt att tro att en ssd skulle leva så pass länge att man slår i taket. Skulle du mot förmodan skriva 20gb/dag vilket är rätt mycket för en normal användare så skulle nandcellerna klara sig i knappt 10 år...
Citera flera
Citera
Skrivet av Frispel:
Nja, om man ska skriva till ett fyllt block där bara delar av datan används (ett delvit tomt men "smutsigt" block) så blir annars proceduren för det blocket:
läs den data som redan finns där -> radera -> skriv den tidigare datan plus den nya.
Då kan man lika gärna slå ihop ett antal halvtomma men "smutsiga" block i ett färre antal fulla och ett antal helt tomma så blir det färre raderingar i framtiden.
Fasst du har ju förlorat möjligheten att skriva in data i de nya blocken som annars hade haft plats över...
Och det blir färre raderingar i framtiden på bekostnad av fler raderingar "nu", dvs. man prioriterar i det fallet prestanda framför nandslitage.
Skrivet av Frispel:
Poängen är återigen att folk inte ska oroa sig för att ssd:n ska dö av utslitna nandceller, den kommer antagligen att dö av liknande saker som andra komponenter dör av. Det är som sagt många som hört att en ssd tål ett begränsat antal skrivningar och då i onödan oroar sig för att deras nya fina ssd ska dö av det. Om siffran inte går att uppnå i verkligheten så beror det nog i så fall huvudsakligen på att ingen/väldigt få skriver så mycket till sin disk
Hör du hur du låter?
"Användarna är oroliga, därför är det berättigat att tillverkarna hittar på siffror för att lura användarna till att tro att det inte är något problem."
Om siffran inte går att uppnå i verkligheten beror det på att siffran var felaktig/missvisande...
Sålänge siffran inte speglar använding i praktiken så är den värdelös. Den duger inte till att lugna oroliga användare och den duger inte för att man ska kunna få ett humm om hur mycket slitage disken tål.
Skrivet av Frispel:
Baserat på det exempel som Anand tar upp så har jag ingen anledning att tro att det är tilltaget i överkant, om något så tror jag att det kan ses som ett minsta värda med god marginal uppåt beroende på hur man använder disken. Men det är antagligen irrelevant då jag har svårt att tro att en ssd skulle leva så pass länge att man slår i taket. Skulle du mot förmodan skriva 20gb/dag vilket är rätt mycket för en normal användare så skulle nandcellerna klara sig i knappt 10 år...
Du antar väldigt mycket...
Citera flera
Citera
Skrivet av echo:
Fasst du har ju förlorat möjligheten att skriva in data i de nya blocken som annars hade haft plats över...
Och det blir färre raderingar i framtiden på bekostnad av fler raderingar "nu", dvs. man prioriterar i det fallet prestanda framför nandslitage.
Faktiskt inte, är blocken halvfulla men ändå "smutsiga" så måste dom raderas ändå innan man kan skriva till dom, om man då kombinerar ihop dom när man ändå håller på så blir det lättare att skriva i framtiden. Alternativen är att trimma block så fort data raderas vilket skulle innebära ett ökat antal raderingar i onödan, eller att vänta med att radera tills oanvänd men "smutsig" plats ska skrivas till vilket skulle ge det scenario som jag beskrev tidigare och som mitt usb-minne verkar hålla på med och som påminner om det som du beskrev...båda de senare alternativen leder till onödigt slitage och i de sista fallet även minskad prestanda. Sedan händer det faktiskt att hela block blir tömda på data på naturlig väg och då blir det ingen write amplification alls Oavsett så är det inte ett så stort problem som du ville få det till tidigare.
Skrivet av echo:
Hör du hur du låter?
"Användarna är oroliga, därför är det berättigat att tillverkarna hittar på siffror för att lura användarna till att tro att det inte är något problem."
Om siffran inte går att uppnå i verkligheten beror det på att siffran var felaktig/missvisande...
Sålänge siffran inte speglar använding i praktiken så är den värdelös. Den duger inte till att lugna oroliga användare och den duger inte för att man ska kunna få ett humm om hur mycket slitage disken tål.
Den är till för att lugna folk som är oroliga för nand-döden, inget annat. Man behöver alltså inte vara mer orolig för att en ssd ska gå sönder än en vanlig hårddisk eller annan komponent i datorn. Är man orolig för komponenters livslängd rent allmänt så ser man till att köpa saker med vettig garantitid. Men visst, om du är en person som skriver väldigt mycket till disken så kan det vara bra att veta hur mycket den tål, om man verkligen jobbar på det så går det nog att uppnå dessa 72tb inom garantitiden.
Skrivet av echo:
Du antar väldigt mycket...
Tja, med tanke på att mina antaganden verkar vara mer baserade på tillgänglig information än dina så skulle jag säga att jag antar mindre än du, om det är väldigt mycket låter jag vara osagt
Citera flera
Citera
Är det någon som faktiskt äger en Crucial M4 (128gb) och har något att säga om den? Tänkte mest om den funkar som den ska utan strul ? Måste beställa en ssd väldigt, väldigt snart
Visa signatur
Citera flera
Citera
- Hur investerar ni?12k
- Behöver en billig kylare för en AM3+ CPU2
- Säkerhetsbrist hos Gigabyte-moderkort berör över 240 modeller13
- EU-länder testar app för åldersverifiering på nätet91
- Quiz: Känner du igen programmen på ikonerna?84
- Drivrutiner till "Xbox Series X/S"-kontroll. Vilka är de senaste?0
- Vad lyssnar du på just nu?15k
- Tråden om Nintendo Switch 23,6k
- Wordle på svenska - ordlig.se9,3k
- När vet man när man ska byta sina musfötter?44
- Säljes Oanvänd Samsung Galaxy Watch8 Classic 46mm
- Köpes Legion Go
- Säljes LG G2 65” OLED Evo – Gaming-TV i Absolut Toppklass!
- Säljes Samsung Galaxy Tab S6 Lite (2024) 4GB 10.4" 64GB Grå
- Säljes ASUS RTC 3060 Dual OC V2 12GB
- Säljes ASUS M32CD-K - i5-7400, 16 gb, 256 ssd, 1060 3 gb
- Köpes Köper: AM5 ryzen 7/9 X3d CPU+ram+moderkort
- Säljes Komplett i5-4670K, Geforce GTX 970 med skärm, tangentbord och mus
- Säljes XFX 6950 XT (MERC 319)
- Säljes Garderobsrensning
- Säkerhetsbrist hos Gigabyte-moderkort berör över 240 modeller13
- Kivra testar att ta betalt för tjänsten107
- Quiz: Känner du igen programmen på ikonerna?84
- Steams nya publiceringsregler kan drabba "vuxenspel"41
- Läkare varnar för riskerna med att använda AI44
- Nvidias nya processor uppskjuten till sent 20268
- Razer lanserar eGPU-kabinett med Thunderbolt 520
- Sverige tappar fart i 5G-racet37
- Veckans fråga: Hur gammal är din router?144
- DDR5-minne överklockas till rekordhastigheter12
Externa nyheter
Spelnyheter från FZ
- FZ High Score – Sista chansen! Tippa Killing Floor 3 och Wuchang igår
- HBO:s The Last of Us tillbaka 2027 – kan avslutas med tredje säsongen igår
- Diskutera – Vilket spel har den bästa sommarkänslan? igår
- FZ High Score – Donkey Kong Bananza-betyget låst, med ny ledare i toppen igår
- Självstyrande bilar till Night City – Cyberpunk 2077 får patch i dag igår
