Det dyker inte upp någon kraftfull APU än på några år hur som helst. Fusion/APU blir till att börja med bara lågprestandadelar med inbyggd GPU i samma kisel.
Sandy Bridge kommer ha 256-bitar bred FPU också, Bulldozers fördel försvinner så fort man börjar använda 256-bitars operationer, eftersom man då inte får in två ops samtidigt. Men det är ju därför de kör dubbla antalet heltalsenheter jämfört mot Intel. FPU var också diskret till att börja med, samma med MMU i många fall, de riktiga förbättringarna kommer flytta in i FPUn inte gpun. Tror inte vi får se integrerade prestandadelar inom överskådlig tid. Systemen har inte bandbredd nog att det ska vara lönt att skicka runt vanlig data mellan cpun och gpun. När det gäller video kan man t ex hålla hela videoarbetet på gpun, där den ändå ska skickas för att visas.
Bulldozer är inte designad för att vara någon APU, det är i princip CMT med dubbla fysiska heltalsenheter och breddad flyttals/vektorenhet där man hoppas att applikationerna fortsätter köra 64/128-bitars SSE för att på det viset komma undan prestandaförlusten. Alltså inte alls designad för att GPUn ska ta över. Även om de räknar med att det är GPUerna som ska hjälpa till för fysik till spel osv, men det är helt rätt plats för att hantera det grafiska, OpenCL och DirectCompute är designade för att användas tillsammans med OpenGL/Direct3D för grafik och hantering av denna, HPC-segmentet använder helt egna bibliotek för att accelerera och göra deras beräkningar på GPUer. Liano APU och Bobcat APU kommer vara lågprestandadelar och mainstream för vanlig netbook/notebook/desktop användning. De kommer alltså inte ens kunna använda gpgpu för spel för de kommer vara för klena. Så jag skulle påstå att det är något helt för GPUerna ett bra tag framöver. Larrabee skrotades så inom överskådlig tid kan vi inte se vad Intel sysslar med förutom deras inbyggda grafikkretsar. Utvecklingen har pågått länge, det var ju trotts allt 5 år sedan de köpte upp Pixomatic och Michael Abrash började jobba för dom. Från hans synvinkel var det bättre om de hade stoppat in funktioner i cpun som kunde hjälpta till med mjukvarurendering. Han syssla ju med mjukvara som skulle användas när grafikdrivarna var trasiga. Tror inte allt flyttar in i gpun bara för att de flyttar över liknande arbete till grafikdrivrutinen. Saken är hur son helst att man inte har tillräckligt med bandbredd i systemen än för att kunna göra saker för att manipulera grafiskt material via cpun, (som ligger i gpun), för att flytta fram och tillbaka data mellan ramminnet och gpuns minne är slött. Därför det hålls separerat.
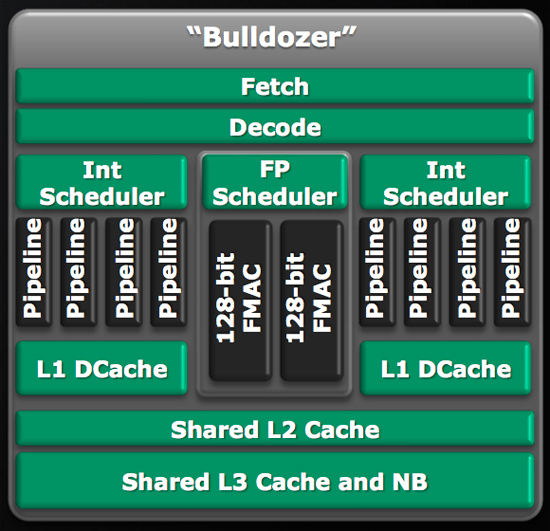
8-core/4-modul bulldozer kommer tävla mot 4-core Intel hur som helst och i mainstream kommer det vara fyra st modifierade K10 mot 2 st Sandy Bridge kärnor. Så antalet flyttalsenheter Bulldozer vs Sandy Brigde kommer ju matcha upp. Anledningen att de gör så är att det inte kräver så mycket yta. För att de inte gillar SMT eller andra multithreadteknologier osv. Vektorenheterna är inte på lång sikt färdigutvecklade för att tas över av diskreta kretsar eller flyttas ur pipelinen. GPGPU passar som sagt bara så länge man kan hålla datan på gpun minne och inte behöver gå fram och tillbaka. AES-NI är en klockren förbättring, trotts att grafikkorten också klarar AES-acceleration. Det används vid uppspelning av blu-ray där. Sen är det ju bara att se på vad CELL fortfarande är kapabel av. SPE-elementen är i princip bara massor vektorenheter. Det betyder för övrigt inte att SPE-elementen inte klarar att hantera heltalsberäkningar. Det klarar GPUerna också, så, så länge det passar arbetsflödet kommer heltalsberäkningar att göras på GPUer också. Precis som flyttalsberäkningar kommer behövas göras i samma pipeline som heltalsberäkningarna i CPUn.
ARM har fått kraftigt förstärkt flyttalsförmåga och extensions de senaste åren trotts hård inbyggnad med gpun som är kapabel av shaders osv.
Bulldozers flyttalsprestanda är hur som helst den dubbla per exeveringsenhet (modul i BD speak) mot K10. Deras plan är som sagt att matcha Intels antal av AVX-kompatibla flyttalsenheter, inte klara sig med mindre. Intel har istället en snabb arkitektur med SMT/hyperthreading som hjälper dom med vanliga flertrådade laster. Det är olika val av flertrådad teknologi bara som jag ser det. Mer prestanda per yta än att bara köra fler kärnor och ett alternativ till att implementera andra flertrådsteknologier. Kan inte läsa in mer i det än så innan det kommer ny arkitektur efter de nästa. gpGPU hör hemma hos gpun och CAD-programmen, moduleringsprogrammen, compositing programmen, videoredigeringssviter, andra grafiska tillämpningar och spel för närvarande. Saker som videoavkodning är fortfarande egna enheter på gpuerna. HPC laster på gpuer hör fortfarande hemma på speciella kort för det. Sen finns det nischer som videokodning (video encoding) på GPUer. Att det används hårt för icke grafisk data kan vi inte förvänta oss på många år. Biblioteken som finns för icke grafiska tillämpningar är ju för nischer som inga hemanvändare och de flesta professionella användare inte kommer pyssla med. Shaders har vi ju för den delen haft även för icke grafiska tillämpningar i år. Revolutionen Intel ville skapa är långt bort. Programvaran för den jobbar de dock vidare på. Branschen utnyttjar ju inte ens gpun ordentligt till alla de grafiska tillämpningarna än. Det är där OpenCL och DirectCompute kommer hjälpa till. Många kommer helt enkelt hoppa över shadersteget nu. Kommer dessutom vara enklare att utveckla mot OpenCL-kapabla kort eftersom man tom kan köra bibliotek ovanpå det som folk faktiskt förstår. Men det är fortfarande nya grejer.