Här kommer en lite längre redogörelse för tester jag kört, inspirerad av ffa @tellus82 s tips på mjukvaror, resonemang om OS-timerinställningar samt frågeställningar att testa. Jag försöker ha underrubriker och fetstilta partier som ska göra inlägget överblickbart trots att det är långt.
TL;DR kommer här direkt för den som är otålig:
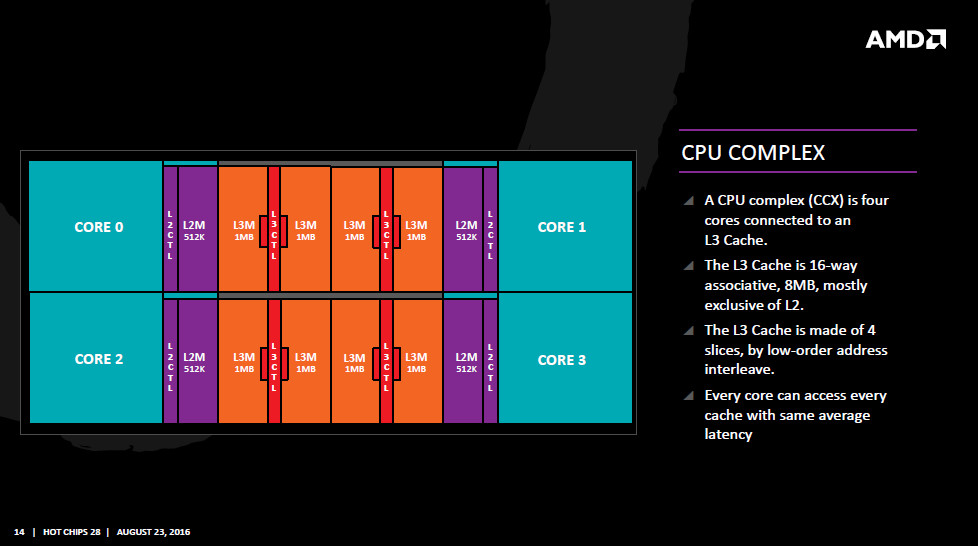
- Tester körda under Windows 8.1 på en 8-kärnig processor som har en liknande cachedesign som Ryzen, med 2st moduler med 4 kärnor och 1st L3$ vardera.
- Vid 0.5ms OS-timer (motsv Win10 game mode) ser vi en 9-10% prestandareduktion i Wprime enkeltrådat jämfört med 15.625ms OS-timer (default i win7-10), men bara om följande villkor är uppfyllda:
Power plan sätts till ”balanced”
Windows inte är medvetet om vilka kärnor som fysiskt sitter tillsammans med gemensam L3$
Trådflytt inte förhindras mha ”thread affinity” i Windows task manager.
- Vid ”high performance” power plan, thread affinity låst till 1 tråd, eller om Windows uppfattar som att de olika processormodulerna (motsv. CCX) sitter på olika socklar, så försvinner prestandareduktionen vid hög OS-timer i stort sett helt.
- Slutsatsen blir att någon slags overhead verkar uppstå då trådar flyttas mellan processormoduler med liknande struktur som Ryzens CCX, men detta fenomen är bara markant när trådparkering är aktivt som strömsparfunktion.
- En ytterligare slutsats, som vi kan extrapolera från dessa resultat, är att trådflytt mellan CCX verkar kunna undvikas om Windows betraktar Ryzens båda CCX som två processorer på var sin sockel (detta oberoende av NUMA).
Inledande teori
Det finns fortfarande ett oförklarat fenomen att vissa spel presterar bättre på Win7 än på Win10 med Ryzen, oberoende av om SMT är påslaget, samt att prestandaskillnaden försvinner eller minskar kraftigt om man slår av ett helt CCX. Andra tester visar att olika laster förbättras eller försämras när ett CCX slås av (i Ryzen master eller Bios), där just spellaster oftare presterar bättre med ett ensamt CCX. En misstänkt optimeringspunkt som diskuterats är hur windows schemalägger trådar och huruvida det faktum att olika kärnor på CCX har olika latens till varandra och olika L3$ bör tillåtas influera schemaläggningen. Samtidigt är AMD inte så intresserade av att diskutera optimering av schemaläggningen, utan de pekar på problem med powermanagementinställningarna, som de arbetar med Microsoft för att reducera. Det har också visats i tester att om man väljer ”High performance mode” i power settings så presterar Ryzen betydligt bättre på Windows 10, vilket också AMD rekommenderar som workaround tills vidare. Diskussioner här i tråden har samtidigt kretsat kring OS-timerns upplösning, vilken vi vet skiljer sig mellan Win7 och Win10. Kan det vara så att den höga OS-timerfrekvensen vid spel under Win10 gör att trådar flyttas oftare mellan CCX, och att detta leder till en märkbar impact under Win10 jämfört med Win7? Det finns också förslag på att schemaläggningen interagerar med power settings, vilket lyfter frågan om en eventuell effekt av OS-timerfrekvens begränsas av vilken power setting man använder. Det blir därför intressant att veta hur OS-timern påverkar prestanda i enkeltrådade CPU-laster, om en sådan effekt interagerar med powerinställningarna, och om effekten har något att göra med Ryzens design med 2st CCX.
I brist på Ryzen-maskin att testa på så har jag kört lite tester på min egen desktop, spel- och virtualiseringslabbrigg, som har den trevliga egenskapen att jag ganska lätt kan emulera en processor med samma cache-hierarki som Ryzen. Primärt gör jag det för att jag inte har någon Ryzen-rigg, men det finns också ett egenvärde i om jag kan replikera fenomen vi ser på Ryzen på en maskin som delar de egenskaper vi tror är relevanta, men som inte är Ryzen. På så vis kan vi verifiera att det är just de aspekter vi misstänker som producerar resultaten, och inte någon annan okänd aspekt av Ryzens arkitektur som vi inte mätt.
Min testrigg
Maskinen är en dual Opteron 6140 (Magny-Cours, AMD K10 45nm). Den hör alltså till generationen Opteron som kom före Bulldozer, ca 2009. Jag har använt den som desktop/arbetsstation samt även spelkonsol tack vara en virtualiserad Windows-instans med dedikerat grafikkort (PCIe passthrough). Varje CPU har 8 kärnor, och är lik Ryzen på ett antal punkter.
Likheter mot Ryzen:
Varje CPU är en MCM med två moduler med 4 kärnor i varje
Moduler på samma sockel kommunicerar med varandra på samma sätt som moduler på olika socklar (man tjänar alltså inget på den fysiska närheten mellan moduler på samma MCM/sockel)
L1&2$ är privat per kärna
L3$ är privat per modul och är en victim-cache till L2
Skillnader mot Ryzen:
Annan mikroarkitektur (K10 vs Zen)
Modulerna kopplas inte samman med en buss, som i Ryzen, utan med dedikerade HyperTransport-länkar mellan varje modul (upp till ett visst antal moduler)
Magny-Cours är NUMA, eftersom varje modul har en egen minneskontroller med 2 kanaler. Att accessa minnesbankar som kontrolleras av andra moduler kostar latens jämfört med att accessa det ”egna” minnet. Men - NUMA går att ”stänga av” (förenklat sett...) till kostnad av en generell latenspenalty, jag har gjort detta för testerna nedan.
Ingen SMT, dvs 1 kärna = 1 tråd
6Mb L3$ / modul varav 1Mb är snoop-filter för att lättare hålla reda på vad som finns cachat i andra L3 (något vi inte hittils fått indikation på att Ryzen har)
På grund av dessa likheter så tycker jag att det är intressant att testa om jag kan replikera fenomen vi ser på Ryzen på denna rigg, särskilt då vi misstänker just cachedesignen vilken här är mer lik Ryzen än någon annan x86-maskin. Vi har alltså moduler om 4 kärnor som delar på en victim-LLC, en skillnad är dock att modulerna kommunicerar oberoende av minnesbussen. Detta tillsammans med snoop-filtret borde innebära något mindre overhead vid kommunikation mellan kärnor på olika moduler, jämfört med Ryzen, men ändå en overhead. Då SMT saknas kan jag inte testa effekter av SMT på/av. Däremot kan jag testa effekter av schemaläggning inom/mellan moduler, vid olika power settings och OS-timers, tack vare testproceduren som @tellus82 beskrivit tidigare. Dessutom, eftersom Windows (8.1) körs som virtuell instans, så kan jag via KVM/libvirt styra hur mycket Windows ”vet” om vilka kärnor som delar LLC (mer om detta nedan).
Frågeställningar
Kan vi på Magny-cours replikera fenomenet att schemaläggning över Ryzens CCX-gräns i vissa fall ger en performance hit, och i så fall uppstår fenomenet oberoende av power settings och OS-timer?
Finns det någon information som Windows 8.1 idag kan läsa direkt från hårdvara, som påverkar schemaläggningen på ett gynnsamt sätt för en processor med modularitet likt Ryzen (2 block med var sin LLC)? (I praktiken – vore det lätt eller svårt att få Windows mer medveten om Ryzens struktur?).
Testuppställning och metod
Moderkort: Supermicro H8DG6
CPU: 2x Opteron 6140 (8core 2.6GHz), totalt 16 kärnor
Minne: 32Gb
OS: Ubuntu 16.10 4.4.0-64 generic (VMhost), Windows 8.1 (VM guest)
NUMA: arkitekturen artificiellt tillplattad och dold för OS (Node interleaving påslaget i BIOS)
Resurser till Windows-VM: 8 kärnor (fysiska kärnor 8-15, alla på fysiska CPU01, isolerade från Linux med isolcpus), 14Gb minne (hugepages, nosharepages, locked), kärnorna fördelade på en eller två (virtuella) socklar beroende på testvillkor (se nedan). HPET exponeras inte för Windows, då det inte verkar vara relevant (tack @Yoshman för redogörelsen).
Vad Windows 8.1 ser:
Virtuellt moderkort: Intel 440FX
Minne: 14Gb
CPU: 8x Magny-cours kärnor med 1 tråd per kärna (cpu-mode=host-passthrough)
CPU-topologi: 1 sockel med 8 kärnor ELLER 2 socklar med 4 kärnor vardera (beroende på testvillkor)
Jag har kört alla tester med Windows 8.1, eftersom det är den enda Windows jag har installerat. Vi har tidigare indikation på att timerinställningarna för OS beter sig liknande på Win8 som på Win10, vilket jag också verifierar nedan.
Bios-inställningen ”node interleaving” gör att minneskontrollerna arbetar ungefär som i raid0, och konsekvensen blir att alla CPU-kärnor har samma latens till allt minne. Det ger en latenspenalty jämfört med att accessa lokalt minne, men ökar total minnesbandbredd något (dock ej linjärt pga latensen). Poängen för detta testet är dock inte prestanda utan att emulera Ryzens minneshierarki, för med denna inställning är det precis som i Ryzen endast L3$ som är privat för varje kluster om 4 kärnor. Då windows får se 8 kärnor från samma sockel så uppfattar windows en miljö som är maximalt lik Ryzen i minneshierarki. Kärnorna på den andra fysiska sockeln stannar helt i Linux.
Topologi-inställningarna är en del av experimentet. Jag resonerade så att den information som windows i dagsläget kan agera på, som ligger närmast Ryzens fysiska struktur, är inte NUMA-information utan information om fysiska socklar. Detta eftersom multicore-system med flera socklar kom före NUMA (före minneskontrollern blev en del av processorn), och Windows kunnat hantera SMP över fysiska socklar åtminstone sedan Windows NT 3.51. Dessutom, som diskuterats i tråden, är Ryzen inte ett NUMA-system utan det är enbart hårdvara upp till L3$ som är modulär per CCX. Detta är exakt vad som typiskt är fallet för icke-NUMA-system med flera socklar och flera hårdvarutrådar per sockel, tex de första Xeon med Intel hypertrheading eller ≥2-kärniga Opteron MP. Detta blir också fallet för de flesta moderna NUMA-system där ”node interleaving” är aktiverat, tex denna testrigg. Därför bör Windows, om det får informationen att systemet har två socklar per CPU-die (1 per CCX i Ryzens fall eller 1 per modul i Magny-cours fall) men inte är NUMA, ha all information det behöver för att implementera eventuella optimeringar relaterat till de separata L3$. Vad Windows gör med sådan information i dagsläget visste jag inte, så att undersöka det var ett delsyfte med testet!
Experiment 1: Påverkas prestanda av OS-timerns upplösning, och hur relaterar detta till power settings och huruvida windows ser processorns två moduler som en eller två processorer?
Utfallsmått: Wprime singeltrådat 32M-test (kvadratrot ur de 32 miljoner första heltalen), tid att avsluta testet (lägre är bättre), median av tre körningar.
Faktorer som jag manipulerat:
OS-timer (15.625 ms vs 0.5 ms) x power plan (high performance vs balanced) x CPU-topologi som windows ser (8 core 2skt vs 8 core flat)
Med 8 core flat ser Windows de 8 kärnorna som att de sitter på en sockel, vid 8 core 2skt ser windows 2 socklar med 4 kärnor i varje (vilka sammanfaller med Magny-cours-modulerna). I det senare fallet har windows i teorin tillgång till informationen att de första och sista 4 cores sitter tillsammans och delar på en L3$ vardera. Det borde finnas anledning att undvika att flytta trådar mellan socklar på ett multi-socket-system, varför jag gissar att Windows schemaläggning tar hänsyn till detta, oberoende av hur Windows i övrigt väljer att balansera trådar över socklarna. Då borde vi inte heller se någon effekt av timern i detta fall, OM effekten av timern har att göra med trådflytt mellan moduler. Detta kan alltså leda till en fingervisning om vad motsvarande topologiinformation borde betyda för Ryzen.
Här följer coreinfo för de båda topologivillkoren.
8 core flat:
AMD Opteron(tm) Processor 6140
AMD64 Family 16 Model 9 Stepping 1, AuthenticAMD
Microcode signature: 01000065
HTT * Multicore
HYPERVISOR * Hypervisor is present
VMX - Supports Intel hardware-assisted virtualization
SVM * Supports AMD hardware-assisted virtualization
X64 * Supports 64-bit mode
SMX - Supports Intel trusted execution
SKINIT - Supports AMD SKINIT
NX * Supports no-execute page protection
SMEP - Supports Supervisor Mode Execution Prevention
SMAP - Supports Supervisor Mode Access Prevention
PAGE1GB * Supports 1 GB large pages
PAE * Supports > 32-bit physical addresses
PAT * Supports Page Attribute Table
PSE * Supports 4 MB pages
PSE36 * Supports > 32-bit address 4 MB pages
PGE * Supports global bit in page tables
SS - Supports bus snooping for cache operations
VME * Supports Virtual-8086 mode
RDWRFSGSBASE - Supports direct GS/FS base access
FPU * Implements i387 floating point instructions
MMX * Supports MMX instruction set
MMXEXT * Implements AMD MMX extensions
3DNOW * Supports 3DNow! instructions
3DNOWEXT * Supports 3DNow! extension instructions
SSE * Supports Streaming SIMD Extensions
SSE2 * Supports Streaming SIMD Extensions 2
SSE3 * Supports Streaming SIMD Extensions 3
SSSE3 - Supports Supplemental SIMD Extensions 3
SSE4a * Supports Streaming SIMDR Extensions 4a
SSE4.1 - Supports Streaming SIMD Extensions 4.1
SSE4.2 - Supports Streaming SIMD Extensions 4.2
AES - Supports AES extensions
AVX - Supports AVX intruction extensions
FMA - Supports FMA extensions using YMM state
MSR * Implements RDMSR/WRMSR instructions
MTRR * Supports Memory Type Range Registers
XSAVE - Supports XSAVE/XRSTOR instructions
OSXSAVE - Supports XSETBV/XGETBV instructions
RDRAND - Supports RDRAND instruction
RDSEED - Supports RDSEED instruction
CMOV * Supports CMOVcc instruction
CLFSH * Supports CLFLUSH instruction
CX8 * Supports compare and exchange 8-byte instructions
CX16 * Supports CMPXCHG16B instruction
BMI1 - Supports bit manipulation extensions 1
BMI2 - Supports bit manipulation extensions 2
ADX - Supports ADCX/ADOX instructions
DCA - Supports prefetch from memory-mapped device
F16C - Supports half-precision instruction
FXSR * Supports FXSAVE/FXSTOR instructions
FFXSR * Supports optimized FXSAVE/FSRSTOR instruction
MONITOR - Supports MONITOR and MWAIT instructions
MOVBE - Supports MOVBE instruction
ERMSB - Supports Enhanced REP MOVSB/STOSB
PCLMULDQ - Supports PCLMULDQ instruction
POPCNT * Supports POPCNT instruction
LZCNT * Supports LZCNT instruction
SEP * Supports fast system call instructions
LAHF-SAHF * Supports LAHF/SAHF instructions in 64-bit mode
HLE - Supports Hardware Lock Elision instructions
RTM - Supports Restricted Transactional Memory instructions
DE * Supports I/O breakpoints including CR4.DE
DTES64 - Can write history of 64-bit branch addresses
DS - Implements memory-resident debug buffer
DS-CPL - Supports Debug Store feature with CPL
PCID - Supports PCIDs and settable CR4.PCIDE
INVPCID - Supports INVPCID instruction
PDCM - Supports Performance Capabilities MSR
RDTSCP - Supports RDTSCP instruction
TSC * Supports RDTSC instruction
TSC-DEADLINE * Local APIC supports one-shot deadline timer
TSC-INVARIANT - TSC runs at constant rate
xTPR - Supports disabling task priority messages
EIST - Supports Enhanced Intel Speedstep
ACPI - Implements MSR for power management
TM - Implements thermal monitor circuitry
TM2 - Implements Thermal Monitor 2 control
APIC * Implements software-accessible local APIC
x2APIC * Supports x2APIC
CNXT-ID - L1 data cache mode adaptive or BIOS
MCE * Supports Machine Check, INT18 and CR4.MCE
MCA * Implements Machine Check Architecture
PBE - Supports use of FERR#/PBE# pin
PSN - Implements 96-bit processor serial number
PREFETCHW * Supports PREFETCHW instruction
Maximum implemented CPUID leaves: 00000005 (Basic), 8000001A (Extended).
Logical to Physical Processor Map:
*------- Physical Processor 0
-*------ Physical Processor 1
--*----- Physical Processor 2
---*---- Physical Processor 3
----*--- Physical Processor 4
-----*-- Physical Processor 5
------*- Physical Processor 6
-------* Physical Processor 7
Logical Processor to Socket Map:
******** Socket 0
Logical Processor to NUMA Node Map:
******** NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
*------- Data Cache 0, Level 1, 64 KB, Assoc 2, LineSize 64
*------- Instruction Cache 0, Level 1, 64 KB, Assoc 2, LineSize 64
*------- Unified Cache 0, Level 2, 512 KB, Assoc 16, LineSize 64
******** Unified Cache 1, Level 3, 10 MB, Assoc 1, LineSize 64
-*------ Data Cache 1, Level 1, 64 KB, Assoc 2, LineSize 64
-*------ Instruction Cache 1, Level 1, 64 KB, Assoc 2, LineSize 64
-*------ Unified Cache 2, Level 2, 512 KB, Assoc 16, LineSize 64
--*----- Data Cache 2, Level 1, 64 KB, Assoc 2, LineSize 64
--*----- Instruction Cache 2, Level 1, 64 KB, Assoc 2, LineSize 64
--*----- Unified Cache 3, Level 2, 512 KB, Assoc 16, LineSize 64
---*---- Data Cache 3, Level 1, 64 KB, Assoc 2, LineSize 64
---*---- Instruction Cache 3, Level 1, 64 KB, Assoc 2, LineSize 64
---*---- Unified Cache 4, Level 2, 512 KB, Assoc 16, LineSize 64
----*--- Data Cache 4, Level 1, 64 KB, Assoc 2, LineSize 64
----*--- Instruction Cache 4, Level 1, 64 KB, Assoc 2, LineSize 64
----*--- Unified Cache 5, Level 2, 512 KB, Assoc 16, LineSize 64
-----*-- Data Cache 5, Level 1, 64 KB, Assoc 2, LineSize 64
-----*-- Instruction Cache 5, Level 1, 64 KB, Assoc 2, LineSize 64
-----*-- Unified Cache 6, Level 2, 512 KB, Assoc 16, LineSize 64
------*- Data Cache 6, Level 1, 64 KB, Assoc 2, LineSize 64
------*- Instruction Cache 6, Level 1, 64 KB, Assoc 2, LineSize 64
------*- Unified Cache 7, Level 2, 512 KB, Assoc 16, LineSize 64
-------* Data Cache 7, Level 1, 64 KB, Assoc 2, LineSize 64
-------* Instruction Cache 7, Level 1, 64 KB, Assoc 2, LineSize 64
-------* Unified Cache 8, Level 2, 512 KB, Assoc 16, LineSize 64
Logical Processor to Group Map:
******** Group 0
Dold text
8 core 2skt:
AMD Opteron(tm) Processor 6140
AMD64 Family 16 Model 9 Stepping 1, AuthenticAMD
Microcode signature: 01000065
HTT * Multicore
HYPERVISOR * Hypervisor is present
VMX - Supports Intel hardware-assisted virtualization
SVM * Supports AMD hardware-assisted virtualization
X64 * Supports 64-bit mode
SMX - Supports Intel trusted execution
SKINIT - Supports AMD SKINIT
NX * Supports no-execute page protection
SMEP - Supports Supervisor Mode Execution Prevention
SMAP - Supports Supervisor Mode Access Prevention
PAGE1GB * Supports 1 GB large pages
PAE * Supports > 32-bit physical addresses
PAT * Supports Page Attribute Table
PSE * Supports 4 MB pages
PSE36 * Supports > 32-bit address 4 MB pages
PGE * Supports global bit in page tables
SS - Supports bus snooping for cache operations
VME * Supports Virtual-8086 mode
RDWRFSGSBASE - Supports direct GS/FS base access
FPU * Implements i387 floating point instructions
MMX * Supports MMX instruction set
MMXEXT * Implements AMD MMX extensions
3DNOW * Supports 3DNow! instructions
3DNOWEXT * Supports 3DNow! extension instructions
SSE * Supports Streaming SIMD Extensions
SSE2 * Supports Streaming SIMD Extensions 2
SSE3 * Supports Streaming SIMD Extensions 3
SSSE3 - Supports Supplemental SIMD Extensions 3
SSE4a * Supports Streaming SIMDR Extensions 4a
SSE4.1 - Supports Streaming SIMD Extensions 4.1
SSE4.2 - Supports Streaming SIMD Extensions 4.2
AES - Supports AES extensions
AVX - Supports AVX intruction extensions
FMA - Supports FMA extensions using YMM state
MSR * Implements RDMSR/WRMSR instructions
MTRR * Supports Memory Type Range Registers
XSAVE - Supports XSAVE/XRSTOR instructions
OSXSAVE - Supports XSETBV/XGETBV instructions
RDRAND - Supports RDRAND instruction
RDSEED - Supports RDSEED instruction
CMOV * Supports CMOVcc instruction
CLFSH * Supports CLFLUSH instruction
CX8 * Supports compare and exchange 8-byte instructions
CX16 * Supports CMPXCHG16B instruction
BMI1 - Supports bit manipulation extensions 1
BMI2 - Supports bit manipulation extensions 2
ADX - Supports ADCX/ADOX instructions
DCA - Supports prefetch from memory-mapped device
F16C - Supports half-precision instruction
FXSR * Supports FXSAVE/FXSTOR instructions
FFXSR * Supports optimized FXSAVE/FSRSTOR instruction
MONITOR - Supports MONITOR and MWAIT instructions
MOVBE - Supports MOVBE instruction
ERMSB - Supports Enhanced REP MOVSB/STOSB
PCLMULDQ - Supports PCLMULDQ instruction
POPCNT * Supports POPCNT instruction
LZCNT * Supports LZCNT instruction
SEP * Supports fast system call instructions
LAHF-SAHF * Supports LAHF/SAHF instructions in 64-bit mode
HLE - Supports Hardware Lock Elision instructions
RTM - Supports Restricted Transactional Memory instructions
DE * Supports I/O breakpoints including CR4.DE
DTES64 - Can write history of 64-bit branch addresses
DS - Implements memory-resident debug buffer
DS-CPL - Supports Debug Store feature with CPL
PCID - Supports PCIDs and settable CR4.PCIDE
INVPCID - Supports INVPCID instruction
PDCM - Supports Performance Capabilities MSR
RDTSCP - Supports RDTSCP instruction
TSC * Supports RDTSC instruction
TSC-DEADLINE * Local APIC supports one-shot deadline timer
TSC-INVARIANT - TSC runs at constant rate
xTPR - Supports disabling task priority messages
EIST - Supports Enhanced Intel Speedstep
ACPI - Implements MSR for power management
TM - Implements thermal monitor circuitry
TM2 - Implements Thermal Monitor 2 control
APIC * Implements software-accessible local APIC
x2APIC * Supports x2APIC
CNXT-ID - L1 data cache mode adaptive or BIOS
MCE * Supports Machine Check, INT18 and CR4.MCE
MCA * Implements Machine Check Architecture
PBE - Supports use of FERR#/PBE# pin
PSN - Implements 96-bit processor serial number
PREFETCHW * Supports PREFETCHW instruction
Maximum implemented CPUID leaves: 00000005 (Basic), 8000001A (Extended).
Logical to Physical Processor Map:
*------- Physical Processor 0
-*------ Physical Processor 1
--*----- Physical Processor 2
---*---- Physical Processor 3
----*--- Physical Processor 4
-----*-- Physical Processor 5
------*- Physical Processor 6
-------* Physical Processor 7
Logical Processor to Socket Map:
****---- Socket 0
----**** Socket 1
Logical Processor to NUMA Node Map:
******** NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
*------- Data Cache 0, Level 1, 64 KB, Assoc 2, LineSize 64
*------- Instruction Cache 0, Level 1, 64 KB, Assoc 2, LineSize 64
*------- Unified Cache 0, Level 2, 512 KB, Assoc 16, LineSize 64
****---- Unified Cache 1, Level 3, 10 MB, Assoc 1, LineSize 64
-*------ Data Cache 1, Level 1, 64 KB, Assoc 2, LineSize 64
-*------ Instruction Cache 1, Level 1, 64 KB, Assoc 2, LineSize 64
-*------ Unified Cache 2, Level 2, 512 KB, Assoc 16, LineSize 64
--*----- Data Cache 2, Level 1, 64 KB, Assoc 2, LineSize 64
--*----- Instruction Cache 2, Level 1, 64 KB, Assoc 2, LineSize 64
--*----- Unified Cache 3, Level 2, 512 KB, Assoc 16, LineSize 64
---*---- Data Cache 3, Level 1, 64 KB, Assoc 2, LineSize 64
---*---- Instruction Cache 3, Level 1, 64 KB, Assoc 2, LineSize 64
---*---- Unified Cache 4, Level 2, 512 KB, Assoc 16, LineSize 64
----*--- Data Cache 4, Level 1, 64 KB, Assoc 2, LineSize 64
----*--- Instruction Cache 4, Level 1, 64 KB, Assoc 2, LineSize 64
----*--- Unified Cache 5, Level 2, 512 KB, Assoc 16, LineSize 64
----**** Unified Cache 6, Level 3, 10 MB, Assoc 1, LineSize 64
-----*-- Data Cache 5, Level 1, 64 KB, Assoc 2, LineSize 64
-----*-- Instruction Cache 5, Level 1, 64 KB, Assoc 2, LineSize 64
-----*-- Unified Cache 7, Level 2, 512 KB, Assoc 16, LineSize 64
------*- Data Cache 6, Level 1, 64 KB, Assoc 2, LineSize 64
------*- Instruction Cache 6, Level 1, 64 KB, Assoc 2, LineSize 64
------*- Unified Cache 8, Level 2, 512 KB, Assoc 16, LineSize 64
-------* Data Cache 7, Level 1, 64 KB, Assoc 2, LineSize 64
-------* Instruction Cache 7, Level 1, 64 KB, Assoc 2, LineSize 64
-------* Unified Cache 9, Level 2, 512 KB, Assoc 16, LineSize 64
Logical Processor to Group Map:
******** Group 0
Dold text
Som synes i den senare så ser Windows två socklar med 4 kärnor i varje, fortfarande inga NUMA-noder, och varje 4 kärnor delar en L3$. Storleken på L3$ beräknas dock fel, coreinfo ser det som att varje sockel har 10Mb (5Mb är korrekt, eftersom 1Mb per modul används som snoop-filter). Storleken enligt coreinfo borde inte spela roll dock.
OS-timer ställs in med programmet TimerTool, powerplan ändras och övervakas mha ParkControl, båda efter tips från @tellus82.
Nedan följer resultatet, jag körde varje testvillkor tre gånger för att få en uppfattning om variabiliteten i resultatet. Medianen i varje villkor (fetstilt) är det värde jag sedan räknar på, men jag listar samtliga körningar så att ni kan se hur mycket det varierar. Kolumnen Running time % penalty är procentuella skillnaden i körtid mellan 15.625ms och 0.5ms (lägre är bättre).
| 8 core 2skt (4core/skt, aware of processor modularity) | | 8core flat (1skt*8core, unaware of processor modularity) |
| 15.625ms | 0.5ms | Running time %penalty | | 15.625ms | 0.5ms | Running time %penalty |
hi perf | 66.36 | 66.38 | 0% | | 64.35 | 64.9 | 1% |
| 66.84 | 66.67 | 0% | | 64.74 | 65.35 | 1% |
| 67.4 | 66.9 | -1% | | 65.57 | 65.89 | 1% |
balanced | 68.83 | 69.01 | 0% | | 66.08 | 73.58 | 11% |
| 69 | 69.03 | 0% | | 66.11 | 73.81 | 12% |
| 69.87 | 69.45 | -1% | | 66.13 | 74.59 | 13% |
Som synes är variabiliteten liten, oftast < 1s. Den intressanta kvadranten är 8 core flat, balanced, 0.5ms, alltså längst ner t.h. i tabellen. Där tar testet 73-74 sekunder istället för 64-66, vilket motsvarar en 12-%ig ökning mot timern inställd på 15.625ms (allt annat hållet lika). Detta är alltså vid ”balanced” powerplan och mer intressant, när Windows inte vet att CPU-kärnorna fysiskt sitter i två moduler.
Vid high performance powerplan försvinner effekten nästan helt, även om det är frestande att tolka den 1%-iga ökningen av körtid som kvarstår som en reliabel effekt. I vilket fall är det en mycket liten effekt, så det är osäkert om den skulle ha genomslag i verkliga applikationer. Det intressanta är här att effekten nästan försvinner vid high performance powerplan. Det verkar som att en eventuell effekt av trådflytt mellan moduler har mer att göra med latenser kopplade till avparkering av kärnor än med tiden det tar att fylla L3$ - men likafullt så finns effekten bara då modulerna inte är kända av OS, så den fysiska moduluppdelningen är relevant på något sätt.
Vi ser också att effekt av timerinställningen helt saknas, oberoende av powerplan, då Windows betraktar var och en av processorns två fysiska moduler som en separat processor. Detta bör rimligen betyda att trådar begränsas av Windows till samma sockel under trådens livslängd. Frågan kvarstår dock – handlar detta om problem med att trådar flyttas mellan processormoduler/CCX, eller har det att göra med någon annan aspekt av processorns modularitet eller Windows hantering av multi-socket? Därför körde jag ett uppföljande experiment.
Experiment 2: Försvinner effekten av OS-timer om trådflytt förhindras på annat sätt än genom att informera Windows om CPU-topologin?
Ett enkelt sätt att testa detta är att låta Windows betrakta processorn som en helt platt 8-kärnig processor med en gemensam L3$ (det som normalt skapar prestandareduktion) men att istället låsa trådens affinity till en CPU-kärna. I följande test körde jag det lite längre 1024M-testet i Wprime, som på min maskin tar 33-35 minuter att slutföra singeltrådat. Jag märkte att Wprimes workertrådar inte ärver affinity av GUI-tråden, så jag satte affinity manuellt till CPU1 (andra kärnan på första modulen) direkt (< 20s) efter att tråden startat. Eftersom den kör så länge är det som händer innan jag hunnit låsa affinity försumbart (jag var för lat för att hitta något mer automatiskt sätt). Således är faktorerna: OS-timer (15.625 ms vs 0.5 ms) x thread affinity (TA set vs TA not set)
Utfallsmått: Wprime 1024M körtid (lägre är bättre)
Resultat för balanced power plan:
8core flat (1skt*8core, unaware of processor modularity) |
| 15.625ms | 0.5ms | Running time %penalty |
balanced, TA not set | 2168.88 | 2394.9 | 10% |
balanced, TA set | 2061.27 | 2068.93 | 0% |
Vi ser här att när Thread affinity för Wprimes arbetartråd är satt till en kärna (villkoret TA set), så försvinner effekten av 0.5ms OS-timer. Så det verkar som att det faktiskt är när trådar flyttas till den andra modulen som prestandatappet uppstår, och ingen annan aspekt av att OS inte känner till processorns interna modularitet.
Sammanfattning
Undersökningen började i konstaterandet att Win10 kör en OS-timer på 0.5ms när spel körs (eller också begär spelen detta själva, jag vet inte), vilket kunde vara en delförklaring för varför flera testare sett ett prestandatapp i Windows 10 jämfört med Windows 7. Jag testade därför om denna timerinställning påverkar enkeltrådprestanda för ett specifikt testprogram (Wprime), och om en sådan påverkan hänger samman dels med modulariteten hos Magny-cours-processorn, dels med Windows powerinställningar.
Slutsatsen blir att trådflytt mellan processormoduler redan på Magny-Cours är relevant för prestanda, men att relevansen mest framträder då power settings står på balanced (förmodligen har det att göra med parkering av trådar). Detta speglar vad jag kan se de olika tester som körts med Ryzen. Detta förklarar AMDs prioritering av powerinställningarna snarare än schemaläggningen, då ett mer gynnsamt powerschema nästan tar bort den kombinerade effekten av OS-timern och modulgränsen.
Ett intressant fynd var att Windows verkar förstå att inte flytta trådar mellan processorsocklar i onödan, något som antagligen kan nyttjas för optimeringar till Ryzen. Att exponera två socklar till Windows verkar som en rimlig trade-off mellan den komplicerade separation som NUMA innebär, och den helt platta $-hierarki som Windows verkar se i Ryzen idag. Dock är det inte uppenbart vilka optimeringar Windows bör göra givet denna info, då optimal schemaläggning antagligen beror både på processorns och på programmets egenskaper. Jag kan tillägga att jag kört några varv med Unigine Heaven och Valley utan att se några tydliga effekter på prestanda beroende på om Windows ser processorn som en eller två socklar (har inte testat mot OS-timern). Dock ser jag vid två socklar att trådarna sprider sig ganska jämt över (de virtuella) socklarna, så att 3 kärnor av 4 belastas på varje ”sockel”. Detta är förmodligen klokt i många fall, då det leder till ett maximalt utnyttjande av L3$ storlek. Frågan kvarstår om egenheter hos Ryzen kommer att göra den policyn mindre självklar, enligt hur vi diskuterat tidigare i tråden.
Resultatet här är alltså baserat på Magny-Cours, som liknar Ryzen i hur kärnor klustras samman inom samma fysiska processordie. Det började med en ide om en möjlig effekt av CCX-modulernas sammankoppling på Ryzen, som jag testade på Magny-Cours och den visade sig finnas även där. Det tyder på att våra gissningar om effekten av Ryzens modularitet är på rätt spår, även om vi också ser att det finns andra faktorer som påverkar, vilka nog är lättare att optimera än schemaläggningen. Det hade varit intressant att se resultatet replikerat på ett Intelsystem med samma modulstruktur, tex en multi-socket Xeon med node interleaving aktiverat, för att se om fenomenet uppstår även där!