Mirror i hårdvara eller med ReFS?
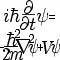

Rädslan att våra diskar skulle ändra data utan att det upptäcks tycker jag är överdriven
Hårddiskar (i detta räknas även SSD och optomedia) har idag väldigt bra felrättning och kontroll på sina sektorer - fel kan det bli, men de går inte oupptäckta förbi...
Typisk disk brukar ha 10^14 bitar per ej korrektebara fel och när det gäller oupptäckt fel och felaktigt rättade fel så är man nere på 1 bitfel per 10^20 bitar - dvs. att få en sektor med oupptäckt fel eller felrättad data är en faktor 1 miljon mer sällan än att du får en helt oläsbar sektor.
För SAS-diskar och Enterprise-diskar så är felsannolikheten satt minst 10^15 bitar per fel, och 10^21 bitar per oupptäckt fel eller felaktigt rättat fel. Felrättningsförmågan på en enterprise-disk är så stor att de kan rätta upp till en hel sektor som förlorats i ett sammanhängande burst-fel på skivan.
För gränssnittet SATA så räknar man med 10^12 bitar per fel. - fel-chansen speglar här att sannolikheten att en sektor i transporten får förändrad data (pga störningar/glapp etc.) med ett bitmönster som ger samma CRC-summa som sektorn med den korrekta datat. Har man inte väldigt många CRC-fel registrerade på kort tid så skulle jag nog säja att felchansen är väldigt liten även här.
hur det är med PCI-länkar (för M:2 etc.) har jag ingen aning - men förmodligen CRC-summor på samma sätt som i SATA.
ECC-minnen har ofta någon variant av hamming-cod eller någon form av CRC, uppbyggda att den kan rätta för ett bitfel, upptäcka fel vid 2 bitfel - är det fler fel än så, samtidigt, så kan resultatet variera.
Media som verkligen skulle behöva filsystem som ReFS, ZFS, BTRFS men inte görs - är när filer lagras på USB-minnen och SD-minnen - där blir det fel ibland för att felrättningsförmågan eller snarare fel-kontrollen av sin egna data är mycket låg eller icke existerande, att korrupta sektorer kan mycket väl levereras utan att mediat meddelar om att denna är felaktig. Det är också mediaformaten där den absolut sämsta flash-minnena hamnar - och därmed också högre risk än i stort sett alla andra medier att det blir fel ibland på dessa - dessa medier är inte ens på nivå floppydisk - för floppydisk har i alla fall CRC-summa på varje sektor och kunde rycka i ett snöre och få uppmärksamhet av OS när det upptäckte fel... medan problemen med SD-minne och USB-minne att även om flashminnet i dessa upptäcker fel (och det gör dom) så är det ingen som lyssnar när de säger till - finns ingen snöre att dra i som någon OS bryr sig om.
---
RAID är motiverbart om maskinen är i konstant produktion och skall kunna fortsätta som inget har hänt även om en lagringsenhet fallerar (förutsätter att man skall kunna byta media under drift, även rent mekanisk med hot-swap av media, att behöva stänga av datorn och mecka ur en disk för att ersätta med en ny - är inte helt lyckat i det läget)
Klarar du nedtid och en återladdning från din backup på rimlig tid ( dvs. i området antal timmar som att skyffla data i hög hastighet från en backup-disk, inte flera dagar som det lätt blir med molnlagring och inte har en mycket snabb lina) så är behovet av RAID inte så stort - vilket gäller vid de flesta privatanvändningar.
Man kan fortfarande ha checksumma etc. på filsystemet om man tycker att det är värt prestandaförlusten - men ärligt, hur ofta har filsystem historiskt gett felaktig data (i avseende silent error - dvs. bitar i en byte har skiftats om utan att systemet har upptäckt det)
Har du UPS, ECC-minne, har du batterbackuppad disk-cache (som också är av ECC-typ) ?? - det är också faktorer som är viktiga om du inte skall få 'tysta' bakgrundsfel.
En av de riktigt besvärliga situationer för en RAID1 av klassisk sort är strömavbrott mitt under skrivning, båda diskarna har skrivit men olika mycket, inga sektorfel finns som kan indikera att datat är korrupt - all dess interna checksummor/ECC indikerar att sektorerna är korrekt skrivna men diskarna är ändå olika - vilken disk är då mest rätt??? det problemet kan inte en RAID1 system lösa själv - och situationen kallas för 'write hole'
Detta är något som plågat nattsömnen hos alla som håller på med RAID i olika konstellationer
Det enda sättet man löst hittills är batteribackuppad ramdisk på SAS/SATA diskkontrollern som skriver till diskarna och håller reda på exakt vilken status diskarna var på när strömmen försvann, och fortsätter där det var när strömmen återkommer igen och diskarna snurrat igång igen.
Zfs sägs ha löst det med olika journaler mm. och har egen kontroll över sin version av RAID-hantering, när det gäller BTRFS är jag mer osäker, men har också egen kontroll över 'sin' version av RAID1 och kör inte klassisk raid1 utan skriver samma fil alltid på två olika media (men inte samma LBA-nummer/sektorposition) och med varsin journal resp media och förmodligen vet vilken som var mest/nyast skriven vid strömavbrottet
Men hur är det ReFS och hur fungerar använda RAID1 (och RAID 5-6 också för den delen) - för är det klassisk soft/HW-raid med sektorspegling i den underliggande disk-lagret under filsystemet så har du ingen extra skydd av en ReFS om den i sin tur bara ser en enda diskyta när den arbetar och inte själv kontrollerar RAID-funktionen.
Kort sagt - har du en RAID-haveri på lägre nivå närmare HW så kommer inte ReFS ens att tillfrågas utan det stannar och ger felrutor långt innan dess...
Samma situation har man om man kör BTRFS eller Zfs på en MD-Raid i Linux (vilket många köpe-NAS gör) - filsystemen har ingen kontroll över själva RAID-systemet och låser sig RAID-systemet för att den är inkonsistent så kan inte ovanpåliggande filsystemen göra något alls - blir inte ens tillfrågad..
Senast redigerat
Citera flera
Citera
ReFS är "designad för att aldrig vara offline"... nu minns jag inte hur man byter ut en fallerad disk, men speglingen är mer för att den ska kunna rätta fel. Jag vet att de är osannolika, men de är ändå helt möjliga. Jag lagrar mycket som inte går att ersätta eller ladda ner på nytt. Ett bitfel i en komprimerad bild kan göra stor skada på bilden. Och om en sektor plötsligt inte kan läsas, så kan ReFS bara skita i det, läsa sektorn från den andra disken, och mappa om datan till en ny sektor.
ReFS skyddar även mot write holes. Därför är jag misstänksam mot hårdvaru-RAID, filsystemet har ingen aning om vad som pågår där, och kan inte hjälpa till om där händer fel. Här har filsystemet koll på allt som händer på de individuella diskarna.
Citera flera
Citera
Oavsett vad som lovas för respektive filsystem så bör man prova det själv först innan skarp drift
tex göra RAID1 av två externa USB-diskar där använda filsystemet får sköta raid-fruktionen.
Sedan medans det skriver och läser tungt med olika programvaror/testsviter så ser man till att glappa med USB-sladden mitt under skrivningen - rycker strömmen på ena disken mitt under skrivningen, båda diskarna samtidigt etc. olika fulheter- och det gör man gång på gång ett antal gånger och sedan ser hur filsystemet repar sig var gång man startar upp det eller om det hänger sig i något läge så man måste använda reparationsverktyg för filsystemet eller om man hamnar i det läget som man absolut inte vill - läget där inte ens OS medföljande program kan reparera systemet.
Definitivt bör man i dessa lägen också prova att byta disk, och se vad som händer om ersättnings-disken är större eller mindre och annan fabrikat än den disken som fallerar/tagits bort och se om det hanterar detta på acceptabelt sätt - det värsta är om disken måste vara exakt på sektorn lika stor som den disken som förlorades för att den skall accepteras i RAID:en - man bör alltid kunna byta till en disk storlek större och den vägen få Raiden skyddad igen. - detta måste man prova - själv!, dels för att lära sig hur man gör rent handgripligen och eventuella kommandon/menyer som är inblandad i detta, men också att försäkra sig att filsystemet klarar av situationen utan problem.
Detta gjorde jag mer eller mindre ofrivillig i början av utvärdering av BTRFS-filsystemet pga. glappande USB3-sladd, ryck ut fel 12V-vårta och en disk i arrayen stannar etc. och efter ett antal sådana händelser (som blev allt mer en avsiktligt testande) konstaterade att BTRFS hanterade situationen bra och därför numera har det som backup/arkiv-format på diskarna eftersom förutom snapshot-hanteringen också är lätt att utöka med flera diskar om backupvolymen och de tidigare snapshot gör att det inte får plats på disken - och hittills har jag inte råkat ut för någon låst och oläsbar filsystem eller dataförlust av filer.
Skulle man lägga samma typ av störningar på NTFS eller ext4 mfl. lite äldre filsystem så hade man förmodligen haft ohjälpligt trasiga filsystem med den behandlingen...
Jag vet inte hur ReFS fungerar vid den typen av användning - men man bör prova själv med ett antal olika 'störningar' för att se hur det självläker sig, om man hamnar i någon icke accessbar läge, och om man hamnar i detta - om och hur de olika filräddningsverktygens förmåga att rädda ut filer ur systemet - tex. BTRFS har ett filextraheringsvertyg för att få ut filerna även om filsystemet i sig är ohjälpligt skadat och inte kan repareras och räddas.
Sådan är jätteviktigt att titta på, till den dagen det skiter sig gruvligt och backuppen inte visade sig fungera och med tanke på att ReFS bara finns i pro-versionerna av Windows och används bara av ett relativt fåtal användare (ännu) så är nog stödet för filräddning mha. olika (kommersiella) program ur ReFS inte så stor.
(Man kan också undra varför inte MS pushar på ReFs till den breda marknaden, och därmed bred användarunderlag och därmed bred kunnande bland användare till den dagen problemen dyker upp, snarare begränsar den ännu mer och låser in denna in dyra pro-versioner och serverversioner av OS - för NTFS behöver verkligen pensioneras, det är en dinosaurie idag som är omplåstrad otaliga gånger... hade inte SSD kommit och gett NTFS en tids respit till, så hade MS varit tvungen att göra något åt det hela för flera år sedan...)
Kort sagt man skall förutsätta och bygga för att det värsta kommer att hända och ändå klara situationen - inte hoppas på att det inte kommer att hända något.
Det betyder att i den ekvationen så finns det alltid en behov av regelbunden backup och helst lagring av dess data på annan ort oavsett hur robust filsystemet är i aktuella server.
Senast redigerat
Citera flera
Citera
- Senaste klarade spel?1,1k
- Vilken bok läste du senast?282
- Årets klipp på 5070 TI eller blåst?36
- Bra plats för hemsida3
- Proton släpper konfidentiell AI-chattbot1
- Windows 11, vilka gamla program fungerar där?11
- DDR6-minne letar sig ut till konsumenter år 202729
- Battlefield 6 avtäcks imorgon58
- [FAQ] Vilken router ska jag köpa?4,6k
- Kraschande RT 9070 XT Sapphire Pulse, tips på lösning?3
- Skänkes Gratis datorprylar – hämtas senast 25 juli kl 09:00 i Göteborg!
- Säljes Stationär gamingdator ev kringutrustning
- Köpes Söker AM4 kit
- Köpes Samsung Ultrawide (G9 eller Neo)
- Köpes Skoldatorer efter tyfon – söker fungerande delar & donatorer till rebuild-projekt
- Säljes ASUS tuf Gaming gt502, i7 14700K, RTX 3080, 32gb
- Skänkes Steam link letar efter nästa ägare
- Säljes Elgato wave panels
- Säljes ASUS TUF RTX 4090 GAMING OC
- Skänkes gratis PSU, moderkort etc
- Proton släpper konfidentiell AI-chattbot1
- DDR6-minne letar sig ut till konsumenter år 202729
- Battlefield 6 avtäcks imorgon58
- Veckans fråga: Vad gör du mest på datorn under sommaren?46
- Okända inloggningar – Ring förnekar intrång13
- Här är Googles Pixel 1016
- Metas nya användarpolicy: betala eller bli spårad110
- Möjlig Radeon RX 7950 XTX-prototyp letar sig ut på nätet18
- Asus lanserar arbetsstation med Nvidia GB300 Blackwell Ultra10
- Så ska Microsoft få bukt med slöhet i Windows 1164
Externa nyheter
Spelnyheter från FZ
