

WS: MSI B350M Mortar | AMD Ryzen 7 1700 | PH-TC14PE | 32GB DDR4 3000MHz | 1TB Kingston NV2 | Intel Arc A750 8GB | 2*BenQ G2420HDB
Router: Gigabyte GA-870-UD3 | AMD Phenom II x6 1055t @ 2600MHz, 1.25V | 12GB DDR3 | 2*250GB HDD @ RAID1 | 4TB HDD
Laptop: Thinkpad X220 4291-QF6
Intel tillkännager Cascade Lake-AP med upp till 48 kärnor och tolv minneskanaler
Visa signatur
Visa signatur
WS: MSI B350M Mortar | AMD Ryzen 7 1700 | PH-TC14PE | 32GB DDR4 3000MHz | 1TB Kingston NV2 | Intel Arc A750 8GB | 2*BenQ G2420HDB
Router: Gigabyte GA-870-UD3 | AMD Phenom II x6 1055t @ 2600MHz, 1.25V | 12GB DDR3 | 2*250GB HDD @ RAID1 | 4TB HDD
Laptop: Thinkpad X220 4291-QF6


Visa signatur
5900X | 6700XT
Visa signatur
WS: MSI B350M Mortar | AMD Ryzen 7 1700 | PH-TC14PE | 32GB DDR4 3000MHz | 1TB Kingston NV2 | Intel Arc A750 8GB | 2*BenQ G2420HDB
Router: Gigabyte GA-870-UD3 | AMD Phenom II x6 1055t @ 2600MHz, 1.25V | 12GB DDR3 | 2*250GB HDD @ RAID1 | 4TB HDD
Laptop: Thinkpad X220 4291-QF6
Visa signatur
WS: MSI B350M Mortar | AMD Ryzen 7 1700 | PH-TC14PE | 32GB DDR4 3000MHz | 1TB Kingston NV2 | Intel Arc A750 8GB | 2*BenQ G2420HDB
Router: Gigabyte GA-870-UD3 | AMD Phenom II x6 1055t @ 2600MHz, 1.25V | 12GB DDR3 | 2*250GB HDD @ RAID1 | 4TB HDD
Laptop: Thinkpad X220 4291-QF6

Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer

Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer

Visa signatur
Fractal Design Meshify 2 Compact w/ Dark Tint | AMD R7 9800X3D | MSI MAG X870 Tomahawk WIFI | 64 GB Corsair DDR5 6000 MHz CL30 | Asus Prime RTX 5070 Ti OC 16GB GDDR7 | 512 GB Samsung Pro 850 SSD + 2TB WD Black + SN850 NVME PCI-E 4.0 | Corsair RM750X |
Visa signatur
5900X | 6700XT
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer

Senast redigerat
Visa signatur
SweClockers Dark Pearl tema: http://www.sweclockers.com/forum/trad/1484891
(Rek. Stylus)
Visa signatur
SweClockers Dark Pearl tema: http://www.sweclockers.com/forum/trad/1484891
(Rek. Stylus)


Senast redigerat
Visa signatur
WS: MSI B350M Mortar | AMD Ryzen 7 1700 | PH-TC14PE | 32GB DDR4 3000MHz | 1TB Kingston NV2 | Intel Arc A750 8GB | 2*BenQ G2420HDB
Router: Gigabyte GA-870-UD3 | AMD Phenom II x6 1055t @ 2600MHz, 1.25V | 12GB DDR3 | 2*250GB HDD @ RAID1 | 4TB HDD
Laptop: Thinkpad X220 4291-QF6


Visa signatur
Tower: ace Battle IV | CPU AMD Phenom II X2 BE unlocked 4cores@3,2GHz | RAM 8GB DDR2@800MHz | MB ASUS M4A785-M | GFK AMD Radeon HD 6850 1GB | HDD Kingston SSD Now 60GB (/) Seagate 2TB(/home) | OS Ubuntu 20.04 LTS
-Numera titulerad: "dator-hipster" då jag har en AMD GPU och dessutom kör Linux.
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
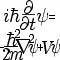
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Senast redigerat
