Skrivet av deadleus:
Vad en processor är snabbast på är den tillämpning den är designat för.
Det låter vettigt. Och ifall M7 är designad för hög genomströmning, så borde den vara snabbare än x86 på det?
Skrivet av deadleus:
Men å andra sidan är jag nyfiken och kanske lika bra och köpa in en M7 och se vad den går för men jag misstänker att det är svårt att få ut den prestanda som kanske finns och Slowlaris har aldrig varit ett roligt alternativ till linux.
Jag tror det är helt onödigt att köpa in en M7, man borde kunna få prova dem tycker man ju, speciellt som att det låter som att ni är ganska stora.
När det gäller Solaris så kan det vara långsammare än Linux. På små laster. Solaris är byggd främst för att skala uppåt till 32-sockets och över. Solaris sweetspot är 32-64 sockets. För decennier sedan fanns det 144-sockets Solaris servrar. Linux är designad för upp till 8-sockets, och sweetspot för Linux är 2-4 sockets. Skälet till det är att det aldrig har funnits större Linux servrar än 8-sockets fram till för några månader sen typ. Linux kernel hackarna utvecklar ju mot de servrar de har tillgång till: sina egna desktops. De har inte tillgång till 8-socket servrar att optimera koden för, än mindre 16-socket eller 32-socket x86 servrar som knappt kommit ut på marknaden.
Eftersom det i decennier existerat stora Solaris servrar leder till att Solaris använder mer komplexa algoritmer i själva operativsystemet, tidskomplexiteten typsikt är O(n logn). Jag läste en blogg om detta, där Oracle fått skriva om stora delar av Solaris för att skala uppåt till 1000 tals trådar. Solaris ser varje tråd som en cpu. Linux använder simpla O(n^2) algoritmer som funkar bra på 1-2 sockets, eftersom Linux utvecklarna har såna hemma. Och typiskt har komplicerade algoritmer som t.ex. O(n logn) större konstanter än simpla algoritmer, detta leder till att Solaris kan ha lägre prestanda på småservrar, men när man börjar öka lasten så drar Solaris ifrån enkelt - eftesrom det är just det som Solaris är byggd för. Flera benchmarks visar att Solaris är snabbare än Linux på exakt samma hårdvara (eller liknande hårdvara) när vi pratar hårdare körning, typ full load på 8-sockets. Och inte typ, en enda tråd som körs under 10 sekunder - där kan Linux vara snabbare. Men det spelar ingen roll vad teorin säger, det enda viktiga är praktiken, så det borde vara enkelt att kompilera om er Linuxmjukvara till Solaris och bencha själv på exakt era laster. Men det beror ju på vad ni har för laster. Rätt vertyg till rätt arbete. Kör ni t.ex. bara Windows grejer så ska man man ju köra x86. Kör ni bara affärssystem som SAP och stora databaser så är valet givet. Men det vore intressant att se om du kunde köra era laster på en SPARC M7, och höra en åsikt från en person som testat såna i verkligheten. Speciellt om ni tycker komprimering och kryptering är viktigt.
Citat:
@MichaelJackson: Jag förstår att du som analytiker i en branch där det finns obegränsat med fiat-pengar siktar på plattformar med hög teoretisk prestanda för maximal utväxling av valuta. Hur nära wall-street fick man bygga en datahall?
Nja, för High Frequency Trading är vi inte intresserade utav hög genomströmning som SPARC M7 är byggd för, M7 är anpassad för stora serverlaster som betjänar många tusen klienter samtidigt. Vi i HFT branschen är intresserade utav låg latency, inte att betjäna många klienter. Därför passar x86 bättre än en servercpu.
"Hur nära Wall Street får man bygga en datahall?" Jag förstår inte frågan. Datahallarna ligger allihopa en bit ifrån Wall Street. Och alla HFT klienter ligger i samma datahall som själva aktiebörsens server, dvs colocation. Det blev gnäll från tradingfirmorna, eftersom vissa HFT klienter ligger nära aktiebörsens server, andra ligger långt bort i samma rum. De HFT klienter som ligger 10m närmre aktiebörsens server, får informationen aningen snabbare, och då kan de fatta ett beslut snabbare och ta aktieaffären som kom in före alla andra. Så börsen fick då ge alla exakt lika långa kablar, typ 100m. Så en HFT klient som ligger nära börsens server, har ändå 100m lina. Då blev det gnäll från somliga HFT klienter, eftersom linan är ihoptvinnad när de ligger nära servern, och när linan är ihoprullad så blir det interferens så signalen störs och deras signal blir aningen försenad på väg till servern. Somliga har alltså sin lina rak, och andra ihoptvinnad. Och rak lina är snabbare. Så börsen började sträcka ut alla linor runt väggarna så de blev raka. etc etc. Vi är inte intresserade av throughput, eftersom en vanlig x86 räcker till. T.ex. all trafik från HFT klienterna och alla andra, till NASDAQs aktieserver, får lätt plats i en 1Gbit lina.
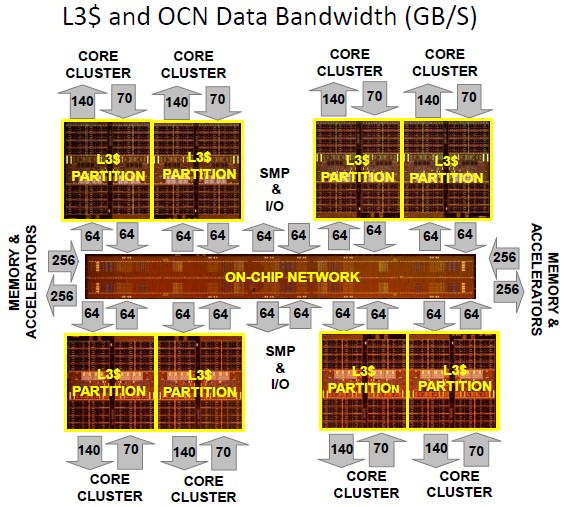
@Yoshman, angående ditt gflops program du skrev ihop. Jag förstår inte riktigt vad du försöker bevisa med det. Jag har sagt att jag inte är intresserad av marknadsföring eller egentillverkade tillrättalagda benchmarks där Intel t.ex. benchar 50 GB direkt från RAM och kallar det Big Data. Det enda som räknas är i praktiken med tester som liknar verkligheten. T.ex. om vi pratar gflops så gäller SPECint2006, Linpack, etc. Ditt program som inte gör något vettig beräkning är alltså inte intressant. T.ex. IBM påstår att deras POWER8 har 230GB/sek bandbredd, och SPARC M7 har 160GB/sek - så ifall du tittar på vad firmorna påstår så ska du köpa POWER8. Men om du istället tittar på riktiga bandbredd benchmarks, så är SPARC M7 dubbelt så snabb än POWER8.
Det är så mycket FUD och aggressiv marknadsföring så man kan inte lita på någon. Det enda man kan lita på, är officiella benchmarks och helst ska man testa själv på exakt sin last. Det är först då man kan dra några vettiga slutsatser. Skit i vad tillverkarna säger. T.ex. IBM påstod att deras gamla POWER6 hade 240GB/sek bandbredd. Det lät som en helt fantastisk siffra och ifall man blint trodde på vad IBM sade, var valet enkelt: köp POWER6. Men jag rotade lite, och det visade sig att IBM kommit fram till den siffran genom att addera bandbredden för L1 cpu cache + L2 cpu cache + L3 cpu cache + RAM bandbredd + etc. Så kan man ju inte göra, det är helt fel om man tänker efter lite. Antag att L1 cpu cache har 1GB/sek bandbredd - då är det en flaskhals och det går inte att vara snabbare än en flaskhals. Om jag ska leverera massa paket genom hela världen, och ifall en av alla kurirer, kan bara hantera ett enda paket per timme eftersom just den kuriren måste passera djungeln, så spelar det ingen roll hur många 1000 kurirer jag har i andra länder. Djungeln är ändå flaskhalsen. Det går inte snabbare än ett paket per timme. Det är flaskhalsen som bestämmer genomströmningshastigheten. Det är en matematisk sanning och går inte att komma runt. Så kort sagt, IBM ljög om den gamla POWER6 minnesbandbredd. Och det är inte första gången IBM ljugit. POWER8s max bandbredd är också en siffra som antagligen bara uppnås i ideala sammanhang med små specialskrivna kodsnuttar, precis som ditt program. Helt ointressant alltså.
Jag är van vid Enterprise världen (där främst IBM ljuger) och jag har lärt mig att det spelar ingen roll vad marknadsföringen och alla specarna säger. För företag ljuger. Och det FUDas friskt. Lita inte på vad någon säger, titta istället på benchmarks och gör egna tester. Om du inte kan göra egna tester, titta på benchmarks. Det är därför jag inte bryr mig om hur många gflops som E5-2699v3 uppnår enligt Intel, och det är därför jag inte kan acceptera dina siffror (som du citerat utav Intel). Det är därför jag vill se riktiga benchmarks. Där har vi facit. Där avslöjas lögnerna. Där ser vi vem som har rätt och vem som är naket klädd. Inget annat kan få mig att ändra uppfattning, oavsett vad företag eller specar säger. Jag är så van vid alla lögner och FUD. Det blir man om man är van vid enterprise marknaden. Det är bara hårda fakta och siffror som gäller. Inget annat. Istället för att debattera inlägg efter inlägg vad Xeon eller SPARC uppnår i teorin, så låt oss posta vettiga benchmarks istället. Siffrorna talar för sig själva. Vi behöver inte göra det. Det spelar ingen roll hur mycket Intel eller du, påstår att E5-2699v3 når 800 gflops, om den i praktiska tester uppnår 400 Gflops, eller om den når dess teoretiska maximum på 281 Gflops pga Amdahls lag, som i den dära länken jag postade.
Det är ungefär som om jag skrev en kodsnutt för AMDs nya GPU som visar att jag kan tända och släcka en pixel säg 25% snabbare än Intel, och drar slutsatsen att AMD är 25% snabbare på FPS också. Ett riktigt FPS spel handlar om så mycket mer än att tända och släcka en pixel, man har fysikmotor, AI, etc etc. Det är helt fel att skriva en liten kodsnutt och extrapolera slutsatser från det, till riktiga FPS spel eller riktiga gflops. Det är som att jämföra äpplen, och sen drar slutsatser om något helt annat, t.ex. päron.
Jag skulle vilja se Tomika köra SPEC2006 benchmarks, eller Lapack, Linpack, etc. Inte några specialskrivna benchmarks som inte gör något vettigt.
Skrivet av Yoshman:
Även i fall 2 finns det fall där Xeon vinner över de andra då den kretsen har mer cache-bandbredd samt mer flyttalskapacitet än även POWER8.
I fall 2), när jag säger hög genomströmning, och när jag pratar om serverlaster, så pratar jag om att betjäna tusentals klienter samtidigt. Det går inte att rymma så stora laster i cachen. Mao, det du pratar om: när lasten rymms i cachen, är fall 1), dvs desktop laster. Du verkar påstå att x86 både har lägre latency och högre genomströmning än SPARC M7?
Sen påstår du att Xeon har mer flyttalskapacitet än SPARC M7, hur når du den slutsatsen? SPARC M7 är ju snabbare än både Xeon och POWER8 i officiella SPECint2006 och SPECfp2006? Det ser ut som att SPARC M7 har mer flyttalskapacitet om vi tittar på benchmarks. Fast det förstås, om vi tittar på vad varje tillverkare påstår och säger - så blir det helt andra resultat. Fast det ska vi inte fästa oss vid, ofta är det överdrivet eller rena lögner. Benchmarks är närmre sanningen än tillverkarnas uppgifter. Det hoppas jag du håller med mig om?
Citat:
Med AVX har Xeon v3 dubbel så hög kapacitet per kärna och klockfrekvens jämfört med POWER8. Och mitt program ovan visar att det är praktiskt möjligt att skriva ett program som nå väldigt nära teoretisk kapacitet med AVX+FMA. Nu räknar inte mitt program ut något vettigt, men även i matrisberäkningar ligger man på upp mot 90% av teoretisk kapacitet.
Jag vill se riktiga benchmarks, och litar inte på att specialskrivna program eller tillverkarnas uppgifter låter en dra slutsatser om hur cpun funkar i verkligheten. Att AnandTech konstaterat att 2699c3 håller 2.8 GHz när alla kärnor jobbar känns irrelevant. Det viktiga är väl ändå hur snabb cpun är, vad den presterar på benchmarks och praktsika tester, inte hur många kärnor den har igång.
Citat:
I servers finns ändå en del problem där det fungerar med många svagare kärnor, men många problem behöver tänka på svarstider och så fort man kommer till punkten att det behövs mer än en CPU-kärna för att lösa ett specifikt problem så blir en stark CPU-tråd alltid mer effekt jämfört med två CPU-trådar med halva kapaciteten.
När du har stora affärsservrar som betjänar 1000 tals klienter samtidigt, så är förstås svarstiden viktig. Men om det redan är tillräckligt låg svarstid så spelar det ingen roll om det klienten blir betjänad på 10 millisekunder eller 20 millisekunder. Mao, svarstiden är inte så viktig om den är tillräckligt låg för att inte upplevas störande för klienten. För affärsservrar gäller normalt andra spelregler än de du är van vid: en x86 server som betjänar 100 klienter på 10 millisekunder var, är en sämre server än en SPARC server som betjänar 5.000 klienter på 20 millisekunder. 50x fler klienter är att föredra, du sparar ganska mycket pengar och ström.
Citat:
Och också en värld där man idag använder ASICs för att kunna nå prestandanivåer som helt enkelt inte är möjlig med generella CPUer.
Jag har hört att ASICs inom HFT inte är jättetrivialt att använda på ett bra sätt, därför att många kör på 1GHz eller så. Och en 4GHz cpu har lägre latency än en 1GHz krets.
Citat:
Är lite det jag är ute efter när jag pekar på att resultaten från flera av "världsrekorden" inte är så relevant (och AnandTech är också väldigt kritisk till dessa benchmarks praktiska värde). Ta t.ex. fallet att Oracle väljer ett Hadoop fall som är otroligt tungt på komprimering, en funktion som alltid är HW-accelerad i SPARC M7. Om man nu har ett sådant problem och väljer Xeon eller POWER så är man idiot om man inte stoppar i t.ex. 89xx-kretsar eller ASICs/FPGAs som accelererar just komprimering. I det läge går det inte något kring hur POWER8/Xeon v3 presterar då ingen verkar postat sådan resultat, man vet i alla fall att det blir signifikant bättre prestanda än vad Oracle nu jämför sig med (och i Xeon-fallet kan man köpa väldigt mycket ASICs/FPGAs innan man matchar effekt och pris av POWER8/SPARC M7).
Visst är det Hadoop fallet tungt på komprimering, komprimering brukar vara det. Men när du säger att "Oracle valt ett sånt specialfall med komprimering som Intel inte har inbyggd så det är orättvist" - så har du fel igen. Oracle redovisar i samma benchmark siffror utan komprimering, och det blir ungefär samma resultat. Vilket är rimligt, Oracle säger ju att komprimering är i stort sett gratis, så då borde det bli samma resultat oavsett om Oracle slår på komprimering eller inte. Och det är precis det Oracle redovisar i benchmarken. Mao, även om SPARC M7 kör icke komprimerat så förändras inte siffrorna, M7 är 5x snabbare även okrypterat. Det vore jobbigt om SPARC M7 slog på kryptering och komprimering, båda ska ju nästan vara gratis så M7 kör nära full hastighet hela tiden oavsett. Men för en x86 kanske prestandan halveras eftersom den komprimerar, och sen halveras en gång till eftersom den krypterar. Då blir en M7 hela 2 x 2 x 5 = 20x snabbare än en x86 cpu. Men visst, börjar du bestycka en x86 cpu med diverse externa kort ändras bilden. Då kanske x86 kan köra i full hastighet eftersom den slipper kryptera och slipper komprimera, så då är SPARC M7 bara 5x snabbare.
SPARC M7 har flera acceleratorer ja: komprimering, kryptering, databas. Förutom dessa fyra, känner jag inte till några andra accelerateror. M7 benchmarksen som Oracle postade använder inte databas acceleratorn i alla benchmarks, bara på några få. Komprimering och kryptering låter M7 kör nära full hastighet, det är inte så att komprimering och kryptering ökar M7s hastighet på Hadoop - de bara låter M7 köra nära full hastighet. Så om du tycker Oracles benchmarks är orättvisa titta istället på okrypterade och okomprimerade resultaten som Oracle alltid(?) postat - då kan du sluta prata om att använda externa kryptokort till x86. Då blandar vi inte in några acceleratorer alls (förutom i databasbenchmarksen).
Citat:
Håller inte med om det sista. Kräver arbetet rå heltalsaritmetik har POWER8 och Xeon v3 signifikant mycket mer kapacitet, kräver arbetet flyttal har Xeon v3 klart högst kapacitet (och pratar om "throughput", inte latens här).
Hur drar du denna slutsats? SPARC M7 är ju mycket snabbare på SPECint och SPECfp benchmarks? Om Xeon har högre heltal och flyttalsprestanda, så borde väl Xeon även vara snabbare på benchmarks som mäter just det? Eller menar du att Xeon har högre teoretisk prestanda? Men med teori skjuter ingen hare. Har du benchmarks som stödjer ditt påstående?
Citat:
Har man problem som inte kan köra på väldigt många CPU-trådar så är Xeon v3 snabbare än de andra i rena heltalsberäkningar, d.v.s finns en rad problem där Xeon i praktiken har högre genomströmning än de andra trots att den rent teoretisk har totalt sett lägre aggregerad heltalskapacitet än både POWER8 och SPARC M7.
Du får gärna visa länkar till en rad sådana problem du pratar om så jag kan lära mig något jag missat.
Citat:
Xeons är populära i HPC för de har högre flyttalskapacitet, är billigare och framförallt har långt bättre perf/W än POWER8 och Oracle SPARC.
Hur drar du den slutsatsen att Xeons har högre flyttalskapacitet när SPARC M7 är mycket snabbare i riktiga SPEC benchmarks?
Xeons är framförallt billiga, och ifall man skulle bygga en superdator med 100.000tals SPARC M7 cpuer skulle priset bli helt oöverkomligt. Men prestandan skulle skjuta i höjden, eftersom en superdator behöver många cores och trådar, enligt beräkningsexperter. Och det är nåt som M7 har i överflöd.
Dessutom är en superdator optimerad för att dra så lite watt som möjligt, jag läste att en stor superdator kan dra 10 megawatt. T.ex. IBMs Blue Gene som fram till för några år sedan hade nr 5 på top500 listan, hade dubbla 750MHz powerpc cpuer som drog väldigt lite watt. Samtidigt som det fanns ganska rejäla Xeons ute på marknaden. Men en M7 superdator skulle dra alldeles för många watt, så det skulle inte funka med en sån superdator.
Citat:
För HPC marknaden är det en självklarhet att man skriver om de kritiska delarna för att maximalt utnyttja de finesser som finns i HW, vilket betyder att till skillnad från många "vanliga" program så kommer HPC alltid utnyttja saker som AVX och FMA.
Sant. Man drar sig inte för att skriva om dem till GPUer också. Om du kan skriva om och få ut 5% högre prestanda så gör man ofta det.
Citat:
Nu vet jag inte exakt vad dessa testar, dock är det "_rate_" varianterna och dessa är gjorda så de skalar totalt linjärt med CPU-kärnor och skalar väl med CPU-trådar då den höga frekvensen och det faktum att det är 32 kärnor med 8 trådar per kärna gör ju "_rate_" fallet till ett "best-case" för SPARC M7. Räknar man ut maximal aggregerad heltalskapacitet så är den som sagt högre för de snabbast POWER8 och SPARC M7 jämfört med de snabbaste Xeon v3.
Om man förstår CPU-design och lite kring hur out-of-order designer fungerar så borde man vara mäkta imponerad över att Xeon och POWER8 är mindre än en faktor två efter SPARC M7 i SPECint2006_rate. I många fall är det teoretiskt omöjligt att nå en IPC över 2,0-2,5. SPARC M7 har 8 trådar på sig att nå en total IPC per kärna av 2,0 (finns bara två heltalspipes), POWER8 har 8 trådar på sig att nå en total IPC per kärna av 8,0 medan Xeon v3 har 2 trådar på sig att nå en total IPC av 5,0.
Då 2699v3 och SPARC M7 har ungefär samma teoretiska flyttalskapacitet, SPECint2006_rate är 1360 för två 2699v3, så 680 per krets (denna benchmark skalar som sagt helt linjärt, skalar även helt linjärt även på kluster). Så visst "vinner" SPARC M7 denna, men förstår man vad detta test gör och under vilka förutsättningar respektive CPU får sitt resultat kan jag inte förstå hur man inte imponeras mest av Xeon v3 här. Skulle man i verkligheten ha något där SPECint2006_rate värdet är relevant så är det bara att bygga ett kluster, när man kommer upp till samma pris och effekt (effekt lär ändå vara det man når först) som ett visst SPARC M7 system så har man många gånger högre SPECint/fp2006_rate värde. Och detta är anledning till varför t.ex. HPC ägs av x86.
Alla numeriska HPC beräkningar som t.ex. CFD eller finansmatematik eller väderleksberäkningar på superdatorer som jag känner till, handlar om att lösa samma diffekvation på ett stort grid. Ju fler cores/trådar desto finmaskigare grid. Det är just därför man har superdatorer, så man kan ha 100.000 cpuer och ännu flera cores och trådar. Superdatorer handlar om just det, lösa samma beräkning på många gridpunkter => många cpus.
Om det nu var istället att en superdator typiskt skulle göra en enda beräkning så snabbt som möjligt (och inte biljoner beräkningar), vore det bättre med en enda cpu klockad med flytande kväve till 7-8 GHz. Men superdatorer ser inte ut så, de har 100.000 tals cpuer och GPUer. Allt för att göra så många beräkningar som möjligt, dvs massiv throughput på kortast tid. Dvs scale-out laster. Och SPECint och SPECfp, mäter exakt det. Så ja, SPEC är en relevant benchmark för tekniska beräkningar. Annars skulle den inte se ut på det sättet, att den skalar utåt.
Och jag har sagt att jag är imponerad hur en 150 watt cpu som Xeon presterar så bra. Men ifall vi pratar om vilken cpu som är mest lämpad för tekniska beräkningar, så verkar det som att SPARC M7 cpun är bättre på det än x86.
Men vill du bygga ett kluster för X kronor som är för beräkningar, så är det en annan fråga som x86 antagligen vinner när det gäller pris/prestanda.
Citat:
POWER8 är snabbare i heltal än Xeon v3 om den kan använda tillräckligt många CPU-trådar. Xeon v3 är bättre på att extrahera parallellism ur varje enskild CPU-tråd dock, så beroende på hur problemet ser ut kan båda modellerna vinna här. SPARC M7 kan också vinna här, men då krävs det problem som är i stort sätt trivial att parallellisera.
Jag tror inte många säger emot att Xeon är bättre på att köra få trådar snabbt, dvs betjäna en enda användare snabbt. Men SPARC och POWER är mer servercpuer dvs tung last 24/7, och då handlar det om att trycka igenom så mycket arbete som möjligt. Så för desktops, dvs en användare som kör några få trådar så är Xeon bäst. För att serva tusentals klienter så är SPARC och POWER bättre. Därför att de är byggda för olika saker.
Citat:
När jag köper en CPU så är enkeltrådprestanda helt överlägset prio#1 därför att jag
Så ifall du fick välja mellan en single core cpu med två överlägset starka trådar, eller en 6-core med 12 hyfsade trådar, skulle du välja single core cpun??? Jag har svårt att tro dig. Visst är du en desktopanvändare, men ändå. Vad ska du med två starka trådar till, du kommer aldrig kunna multitaska bra. Om man tittar i task manager, så startar Windows upp många trådar, typ 100 eller så, vill jag minnas. Jag gissar att Linux gör detsamma? Som singleanvändare vill du ha ett responsivt system, det får du aldrig med en enda uberstark tråd.
Citat:
...och det helt eller nästan helt saknas beroenden mellan respektive transaktion. Är detta tillägg som gör det till en så pass smal nisch att Intel för tillfället har 95% av servermarknaden. POWER8 och SPARC M7 har högre teoretisk kapacitet per CPU, men de problem där dual socket Xeon inte räcker (har läst något att strax över 90% av de 95% Intel har är dual socket E5 eller single socket Xeon E3) går i väldigt många fall att hantera med flera CPUer eller fix-function accelerationer likt Microsofts FPGAer som används för att ranka sökträffar i Bing.
Helt korrekt att Intel har stor del av servermarknaden idag. Men då pratar vi småservrar, low end. När vi pratar highend, så har Intel ungefär 0%. Fram till nyligen fanns inga 16 socket Intel servrar. Och de som precis har släppts, har väl knappt hunnit någon köpa än. High end servermarknaden ägs till 100% utav Unix och Mainframes. Och när det gäller att betjäna 100.000 tals klienter så är det bara Unix och Mainframes som gäller. Intel går inte, kan inte.
Citat:
Intel kör Linux på Xeon Phi
Jovisst, men ingen säljer en Xeon Phi dator där Phi är den enda cpun. På samma sätt säljer ingen en dator där AMD Fury X är den enda cpun. Mao, det är fel att säga att Phi och AMD Fury X är cpuer. De är hjälpcpuer, de driver inte en dator själv, de skulle vara urusla på det.
Du säger att AMD Fury X också är världens snabbaste cpu på sin nisch precis som SPARC M7, men AMD Fury X är ingen cpu. Så tycker inte du kan säga så.
(SPARC M7 är inte så extremt nischad heller, på alla laster där det gäller att betjäna så många klienter som möjligt, är M7 mycket snabbare än allt annat på marknaden)
Citat:
Din tråd, du får ha vilken titel du vill för min del
Snällt! Kommer du komma med invändning efter invändning i långbänk om jag ändrar trådens titel då? Du ser vitt skilda benchmarks här, över 20st, och jag personligen förstår jag inte vad det är att invända emot hårda fakta, men du accepterar inte benchmarksen. Pga titeln. Men om titeln ändras, så slutar du försöka invalidera alla benchmarksen? Då kan du acceptera dem?
Citat:
"Världens snabbaste server-cpu" är lite mer korrekt för tvivlar att SPARC M7 skulle vara ens i närhet snabbast på någon desktoplast, finns dock väldigt många serverlaster den inte är snabbast på.
Du får gärna visa några serverlaster som SPARC M7 inte är snabbast på. Har svårt att tro att du hittar några, eftersom inte många benchamrks är släppta. Har du blogg inlägg där folk säger att M7 är långsam, då? Foruminlägg? Något som helst bevis att M7 är långsam?
Citat:
Jag menar bara att som setup:en är nu så är den slutsats man drar helt meningslös. För de som använder Hadoop spelar det noll roll om det är en eller hundra CPU-noder, Hadoop kräver ju överhuvudtaget inte cache-koherens mellan noderna så ett bra designat Hadoop system ska vara ett kluster då ett stort cc-NUMA kommer aldrig vara lika snabbt som ett kluster med lika många CPU-kärnor på den här typen av problem.
Har ingen invändning mot att SPARC M7 presterar bäst per CPU-socket här, är bara ett totalt meningslös resultat. Hadoop är något man skalar med "scale-out", inte "scale-up" så även om man pratar "stora" system så kommer det i princip alltid gå att bygga ett snabbare Hadoop system med x86 än med SPARC inom en viss effektbudget eller kostnadsbudget. Så vad har resultatet för värde om det inte finns någon rationell anledning att bygga sitt Hadoop system med SPARC M7?
Du har haft flera invändningar emot att SPARC M7 presterar bäst per cpu socket här. Jag tror poängen med benchmarksen är att Oracle vill visa att M7 är snabb på mycket stora laster. Vilket den är byggd för. 10 TB data att hantera för 4 cpuer torde anses som mycket stor last.
Citat:
Är inte helt med på vad man kan göra med en stor Unix-server som man inte kan göra med Xeon E7. Är fullt medveten om att Xeon E5 inte alls har samma RAS funktioner som POWER8 och SPARC M7, men är just där den stora skillnaden mellan Xeon E5 och E7 ligger, den senare har massor med funktioner för att upptäcka och reparera en lång rad fel. Xeon E5 har väldigt begränsat stöd för "hot-swap", i Xeon E7 server kan man byta PCIe-kort, man kan ta bort / lägga till både CPUer och RAM under drift m.m.
Världens stora datacenter är inte byggda med Xeon E5, de är byggda med Xeon E7. Varför bygger man inte dessa med POWER och SPARC om de skulle vara så mycket bättre?
Med Unix servrar och Mainframes kan du byta allt under drift. Stoppa och starta cpuer under drift, RAM minnen, moderkort, etc etc. Mycket är dubblerat, ibland tripplat. Databussarna har ECC checksums på allting, etc etc. Nu pratar vi bara RAS.
Om vi pratar prestanda så har en stor Unix server mycket högre prestanda än en Xeon E7. Kolla bara på t.ex. SAP benchmarksen. SPARC 32-sockets ligger på 844.000 saps medan x86 ligger kring 300-400.000. Och SAP skalar dåligt, pga det är en scale-up arbetslast. Det går inte att köra scale-out på SAP. (SAP Hana är en annan sak, det är en klustrad in memory dvs read-only databas som används endast för analyser, inte för att göra riktigt SAP arbete).
Skälet att världens stora datacenter är byggda med E5 och inte E7 är talande. Skillnaden mellan E5 och E7 är att E7 skalar upp till 8 sockets. E5 skalar upp till 4 sockets. Annars är det inte jättestor skillnad mellan dem. Så när datacentren nöjer sig med E5, så betyder det att det är massor med småservrar, 2 sockets eller så. Det är en helt enkelt ekonomifråga. En 8-socket server är mycket dyrare än 4st 2-socket servrar. Och eftersom de kör småservrar, så är det scale-out laster, dvs klustrade laster. Precis som Google, Facebook, etc.
Klustrade laster är mer kostnadseffektivt är scale-up laster. Man vill gå mot klustrat när helst det är möjligt. Det är billigare med många småservrar än en enda stor server. T.ex. IBMs P595 POWER6 server med 32-sockets kostade $35 miljoner, dvs en kvarts miljard listpris. Men du kunde köpt 64st x86 servrar för mycket mindre, och fått mer cpu kapacitet.
Så varför existerar det ens en marknad med 16 eller 32 socket Unix / Mainframes som är svindyra, dvs flera 10 miljoner kr för en enda server, när du kan få ett helt gäng billigare x86 servrar med mer cpu kapacitet för en bråkdel av pengarna? Det finns vissa arbetslaster som inte kan köras klustrat. Det är typiskt affärsystem som SAP och stora databaser. Där har du inget annat val än en enda stor scale-up server med 16- eller 32-sockets. Och ju fler sockets, så ökar priset exponentiellt typ. Och alla vill slippa såna här svindyra scale-up servrar. Vad händer om den kraschar, då stannar hela företaget. Det är bättre med ett billigt kluster och ifall en x86 server kraschar så gör det inget, man byter nod. Precis som Google gör. Jag hörde att de har runt 1 miljon servrar.
Ifall man kan kan, så väljer man billiga scale-out kluster 10 ggr av 10. Man undviker i det längsta scale-up servrar, för de är svindyra och single-point-of-failure. Men alla tillverkare vill in dit, för marginalerna är skyhöga och de kan kräva flera miljoner för en enda server. Många tillverkare vill lämna x86 marknaden för marginalerna är typ 3% eller så, de tjänar ingenting. IBM sålde sin x86 division till Lenovo. HP ville sälja sin x86 division. etc etc. High end är där alla stora pengarna finns.
Citat:
Tror du missförstår vad det Agner Fog gjort, han har inte skapat en teori, han har precis som mitt program ovan, verifierat vilken kapacitet man får i verkliga program på i princip alla x86 instruktioner som finns och har med beräkningar och synkronisering att göra.
Men om man nu verkligen kan uppnå den prestanda i verkliga program som Agner Fog och du påstår, så borde det finnas benchmarks. Men det finns inte. Varför? Då har vi minst två förklaringar:
1) Agner Fog och ditt program är inte representativt för verkliga laster.
2) Ni två har rätt, det är bara det alla andra är klåpare som inte lyckas pressa ut 800 gflops i verkligheten.
Vad tror du är mest troligt till varför det inte finns benchmarks som stödjer era påståenden? Det kanske finns någon annan troligare förklaring, isåfall vill jag gärna höra den. Kanske @Tomika kan köra lite SPEC2006 eller lapack eller linpack på sin dator?
Citat:
Och trots att Xeon är långsammast här måste du ändå hålla med om att den imponerar. Den får i praktiken extremt nära 100% av sin teoretiska bandbredd. De andra två har en bit kvar till sina teoretiska värden i praktiken. SPARC M7 når ca 80% av sitt max vilket ändå är helt OK. Betänk att denna typ av test är ett test där flera trådar per CPU-kärna hjälper till, Intel fixar sitt resultat med två trådar per kärna de andra har åtta trådar...
Jag har aldrig sagt att jag INTE är imponerad av Xeon. Det är som en 150 watt AMD graffe skulle vara nästan lika snabb som en 250 watt NVidia graffe ur samma generation - vem skulle inte bli imponerad?
Citat:
Har som sagt skrivit ett program ovan. Men är väl inte så konstigt ändå? Man kan se AVX och FMA som en form av fixed-function teknik, sådan har typiskt en tiopotens eller mer bättre perf/W än att göra samma sak med en generell CPU....Tar man bort AVX så är det samma prestanda per CPU-kärna och klockcykel i POWER8 som Xeon, SSE mot VMX + att båda har två FMA-enheter per kärna.
Jag läste en lång teknisk diskussion där några snubbar som jobbade med vetenskapliga beräkningar diskuterade detta. Kontentan var att man inte alltid kunde använda Intels specialfunktioner, tvärtom påstod nån att det var ovanligt i riktiga beräkningslaster att man kunde använda specialfunktionerna. Och det var därför man inte fick ut mer än 400 gflops. I vissa enskilda moment kunde du använda specialfunktionerna men det var mycket sällan, och påverkade inte resultatet nämnvärt i slutet. Om detta är sant, så kan det förklara varför det inte finns några riktiga benchmarks (som utför många moment) som får ut mer än 400 gflops (vilket är väldigt bra för en 150 watt cpu) i verkliga laster.
Citat:
Jag trodde inte detta, jag i princip vet att det Agner Fog skriver är korrekt (har inte hittat något han hävdar som inte stämmer än). Han hade redan visat att Haswell kan utföra två FMA på AVX register per cykel. AnandTech har visat att 2699v3 kan hålla 2,8 GHz när alla 18 kärnorna är aktiva.
Men det finns inga benchmarks som stödjer 800 gflops. Det enda viktiga måste väl ändå vara benchmarks? Det borde inte spela någon roll hur mycket tillverkarna ljugit ihop? Varken IBM, Intel eller Oracle?
Citat:
Väldigt många har dömt ut mainframes de senaste 30 åren, ändå finns de kvar. Har aldrig jobbat med eller ens varit nära en mainframe (vad jag vet). Men uppenbarligen finns det tillräckligt många som anser att de måste köra dessa system att IBM fortsätter utveckla dessa.
Mainframes har en otrolig inlåsningseffekt. Och de funkar bra för det de är skapta för, dvs batch jobb som körs över natten: "uppdatera detta konto med 2%" och upprepa för miljoner konton. Generellt tror jag att om något är skapt för en specifik grej, så borde den vara bra på det.
Men Mainframes har ingen fokus på t.ex latency, t.ex. det finns ingen aktiebörs som kör Mainframes. Om Mainframes hade lägre latency skulle aktiebörserna switcha till Mainframes omedelbart. Mainframes används inom bankvärlden, inte inom finansvärlden.
Mainframes har otrolig bakåtkomptabilitet, kod från 1970 kan fortfarande köras omodifierat. Det är Enterprise, långa supportcykler på decennier. Enormt bra RAS, de kraschar sällan.
Överlägsen I/O. 296.000 I/O kanaler för en enda Mainframe.
Problemet är att de är svindyra och enorm inlåsningseffekt. Din kod kan inte portas enkelt till andra system. Många Enerprise företag försöker gå ifrån mainframes så fort de kan. IBM säljer Mainframes främst till gamla kunder som uppgraderar. Det är inte många nya Mainframe kunder. Jag själv skulle valt ett kluster med billiga 2-socket x86 servrar om jag skulle gjort något själv idag. Om jag måste köra stora affärssytem med extrema prestanda så är det SPARC M7 som gäller, men det är högst otroligt att jag skulle göra det. Jag tror x86 är bästa valet idag, om man inte har konstiga krav.
Citat:
Vem bestämmer när det är "big-data"? De benchmarks Oracle visade upp verkar använda 10 TB och på de storlekarna är det definitivt möjligt att göra realtidsanalys.
Gränsen flyttas fram hela tiden, och beroende på vem du pratar med kan du göra i realtid, med andra användare kan du inte göra det. Pratar vi många PB så blir det svårt med realtid, annat om du inte stoppar in 1 miljon servrar, etc. Så visst går det med realtidsanalys, du har rätt. Det beror helt enkelt på vems definition man använder. Men inte många skulle säga att 50 GB som kan köras från RAM, är Big Data.
Citat:
Finns inga "scale-up" servers med 10,000 tals kärnor från SGI.
Jag vill minnas att du påstått det tidigare? Tillsammans med fultra? Flera personer har sagt att jag har fel, att SGI UV2000 är en scale-up server. När jag bett dem visa scale-up benchmarks som t.ex. SAP, har ingen lyckats. Men de har ändå hävdat att det är en scale-up server, trots att SGI UV2000 inte kan köra scale-up laster som t.ex. SAP. SGI själva har sagt att UV2000 inte kan det, men det vill de inte lyssna på. De länkarna är helt orelevanta säger Linux fanboysen. SGI har fel, säger de. När jag hävdar att det enda riktiga är benchmarks, så har jag fel. Och så börjar de skriva drivor om teori och siffror, och alltså har de rätt och jag har fel. Men var är benchmarksen då? Finns det några kunder som kör UV2000 till SAP, någonstans på internet? Nej. Inga SAP historier någonstans, inga use cases på SGIs hemsida där kunder kör affärsystem, alla SGIs UV2000 kunder kör uteslutande HPC beräkningar. Var inte du en av dem som sade just det här?
Citat:
Och vad jag pekat på är just att det går att skala x86 till 32 sockets i "scale-up" ledd. Tydligen så stödjer man upp till 64 sockets, men finns "bara" system med upp till 32-sockets som är certifierade för Oracles (300RL) och SAPs (300H) programvaror.
Vad jag vet (och jag är ganska påläst om high end Enterprise) så är det bara SGI som i decennier försökt ta sig in på high end marknaden, som ska släppa en 32-socket server. HP har sin Kraken 16-socket server som är baserad på en gammal Unix 64-socket server som byggts om till x86. Bullion har sin 16-socket server, som presterar kasst. Jag tror mest på HP här, de har länge byggt stora 64-socket Unix scale-up servrar och kan detta. SGI har aldrig byggt såna, och antagligen presterar SGIs server kasst på allt som inte är klustrade laster. Detta är första generationen från SGI som håller på att komma ut nu, vi får vänta 3-4 generationer innan SGI börjar lära sig bygga effektiva servrar. Sen måste även Windows och Linux skrivas om, och det kräver mycket jobb. Nyligen fick Solaris och AIX skrivas om för att hantera 10 tals TB RAM, trots att de båda i decennier hanterat stora servrar. Linux och Windows är klient desktop OS, och de måste nu försöka ta steget in till High end, det är inte alls trivialt, det kommer ta decennier innan de är i Unix klass. T.ex. Linux Big Tux fick 40% cpu utilization under max last, enligt HPs tester. Att Linux ska gå upp mer än så, blir svårt. Linux kernel hackare har inte tillgång till stora 32-socket servrar, hur ska de optimera Linux till 32-sockets? De servrarna existerar ju inte ens knappt.
https://www.sgi.com/solutions/sap_hana/
Citat:
Svårt att se hur en "scale-up" server med 32 st E7 8890 v3 och 64 TB RAM kan vara en "liten" server. Hur stora saker går att bygga med POWER och SPARC, vilka RAS funktioner har de som saknas i Xone E7?
En sådan E7 server vore inte liten alls! Det vore en helt anständig scale-up server. Jag ser två problem:
1) Det vore en bra server, förutsatt att den funkade lika bra som en Unix server som skalat i decennier till 32 sockets. Det går inte i en handvändning att skala upp till 32 sockets. HP som kan sånt här sedan decennier, har börjat med en 16-socket Kraken server för x86, trots att samma server byggd på Itanium gick upp till 64-sockets. Nästa HP generation kanske går upp till 32-sockets?
2) Det finns ingen sån server du beskriver. SGI UV300H med 32-sockets kommer närmast, alla andra x86 servrar stannar på 16-sockets. SGI UV300H går upp till 24 TB RAM.
Jag tror inte att SGIs 32-socket server presterar bra. Jag vill se benchmarks. Antagligen släpper inte SGI några scale-up benchmarks med sin UV300H, pga den presterar dåligt. Om UV300H presterade bra, skulle SGI bomba internet med sina benchmarks, men det lär inte hända. Jag tror att nästa generation UV300H så börjar vi se generella benchmarks med olika scale-up benchmarks. Men inte nu, SGI har fullt upp med att få den att funka och fixa alla flaskhalsar. Optimering kommer nästa generation. Idag släpper väl SGI någon enstaka scale-out klustrad benchmark gissar jag.
Det är som när ryska företaget skulle släppa sin Metro 2033 serie med FPS spel. Deras första grafikmotor var ju kass. Det tog några generationer, och ändå är inte de ikapp Unreal 4 motorn. Och hårdvaruservrar har längre ledtider än mjukvara. Om nu Metro 2033 har haft problem i alla år att komma ikapp Unreal 4 motorn, så hur många år kommer inte SGI ha problem att komma ikapp stora Unix servrar som har flera decennier försprång? Men det spelar ingen roll vad jag tycker, det enda som räknas är praktiska resultat. Om SGIs UV300H presterar benchmarks som utklassar Unix så ändrar jag förstås mig omedelbart. Då säger jag att jag har fel och jag måste omvärdera x86, för då har vi en ny spelare på high end marknaden - men det är högst orimligt idag, med tanke på att det tar lång tid att skala väl.
EDIT: Ny benchmarks släppt. SPECjbb2015, så om man är intresserad av att köra Java på en server, så är M7 ungefär 2.5x - 4.2x snabbare än E5-2699v3