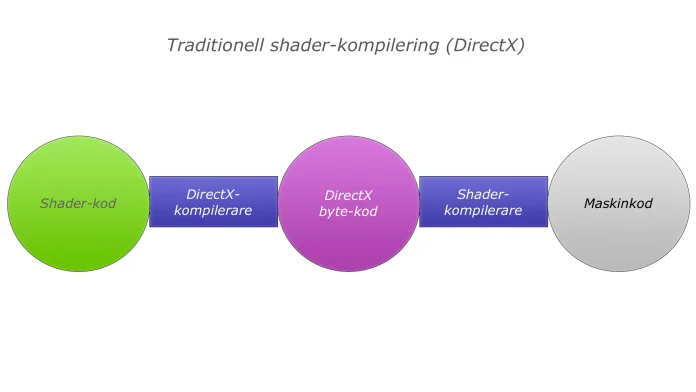
Det är väl inte mycket mer annorlunda än att man använder olika features inom dx 11. I de fallen frågar man drivrutinen vilket stöd det finns för olika funktioner inom versionen av dx och använder de som man har stöd för. Om man nu råkar ha stöd för dessa också, och har förkompilerad shaderkod för många olika GPU:er, så är väl detta inget konstigt? Jag gissar att det kommer finnas i högnivå-språk med verktyg för att förkompilera sådan shaderkod för olika GPU:er.
Det är utvecklarna som har önskat högre kontroll och nu har de fått det. De behöver inte inte använda det. De kan lika bra tuffa på utan det ifall de vill. De kan köra HLSL och DX11 i stället om de nu skulle vilja det. Det är inget måste att göra det här utan snarare en möjlighet.
Du måste inte använda hissen, du kan ta trappan i stället.