@Radolov: angående Hardware Unboxed vs TechSpot, är väl medveten om deras upplägg men är så pass gammal att jag i princip alltid föredrar text-versionen av en artikel jämfört med att se det som en video, speciellt när det handlar om tester.
Så vitt jag sett är TechSpot-artiklarna identisk med motsvarande Hardware Uboxed video när det kommer till innehåll.
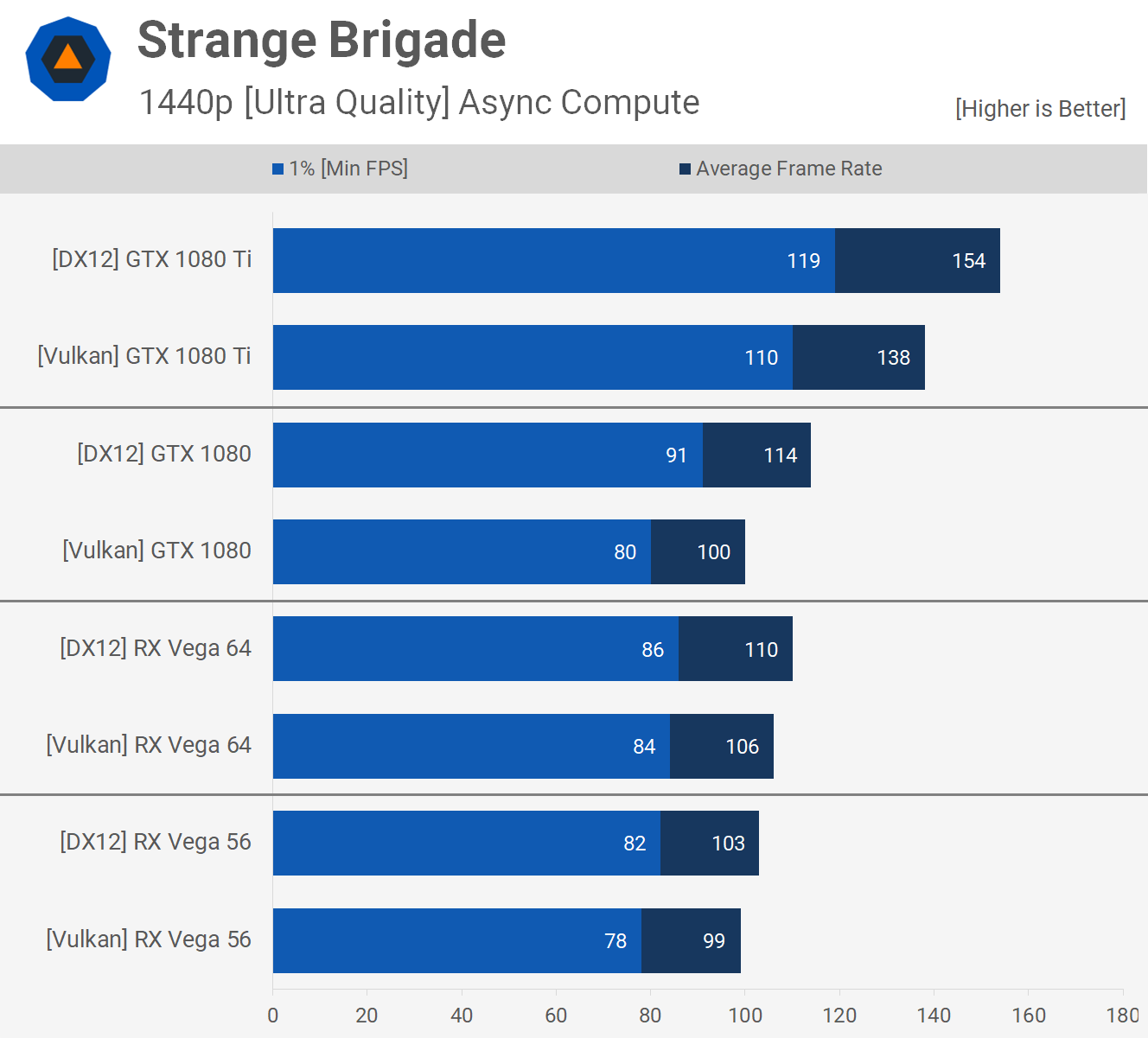
Du pekar på huvudproblemet med "async compute": det är relativt komplicerat att använda och inte alls säkert att man ens får en prestandavinst i slutändan. När det ändå ger en prestandavinst handlar det på PC-sidan om ett par procentenheter. Därför inte speciellt förvånande att det inte riktigt ses som en "killer feature".
Det pratades om 20-30 % prestandavinst med "async compute", det är vad jag förstår också vad man typiskt ser på konsoler. Den stora skillnaden är att på PC är nästan alltid GPU-delen flaskhals medan på konsolerna är nästan alltid CPU-delen flaskhals. Är GPU-delen flaskhals är det ju bara väldigt speciella fall där det kan vara en fördel att lägga ännu mer jobb på GPU!!!
Nvidias Turing-serie kommer med rätt stor sannolikhet göra "async compute" (och därmed DX12/Vulkan) betydligt mer main-stream. Detta då Turing i praktiken består av tre rätt oberoende delar, SMs, Tensor-cores samt RT-cores. Ska man få någon effektivitet alls från Turing måste ju dessa tre delar användas parallellt så mycket som möjligt, då de är oberoende kommer "async compute" ge en massiv prestandavinst mot vad man skulle se med en rent seriell hantering.
En stor skillnad med Turing är dock att "async compute" kommer vara rätt automatiskt där. Utvecklarna jobbar egentligen bara mot Direct X Raytracing APIet (är även på väg för Vulkan i form av "Vulkan RT"), så man slipper hantera de håriga detaljerna.
Just håriga detaljer är är huvudproblemet med DX12/Vulkan. Av vad jag kunnat läsa mig till är dessa två APIer funktionellt extremt nära varandra. Så inte förvånande att vi ser rätt liten prestandaskillnad mellan dessa.
Personligen hoppas jag Vulkan "vinner" då jag föredrar Linux, men tror tyvärr det är rätt osannolikt då spel nästan uteslutande utvecklas på Windows i Visual Studio där verktygen för DX historiskt alltid legat snäppet före andra APIer. Tror därför ändå att DX12 i praktiken kommer ha en liten prestandafördel, det enbart då AMD/Nvidia/Intel kommer lägga mer resurser på att optimera dessa då den marknaden lär komma bli större.
Just att dessa två APIer är så väldigt ner på detaljer gör ändå Apples beslut att köra med Metal rätt lätt att förstå. Metal är mer som OpenGL/DX11 där man fixat bristerna men ändå behållit ett "högnivå API", medan DX12/Vulkan dumpar allt för mycket i knät på spelutvecklarna. Rent praktiskt undrar jag om det finns någon relevant fördel med DX12/Vulkan modellen, den är garanterat dyrare att använda!!!
Angående DX12/Vulkans möjlighet att skala saker över kärnor. Här var förväntningarna totalt fel ställda bland folk på teknikforum likt detta. Finns ingen i dessa som magiskt skulle göra det lätt att köra över väldigt många kärnor, så här långt har vi i flera fall sett det omvända då multi-core optimeringar är extremt dyrt att göra och i spel kommer man med dagens förutsättning aldrig få någon gigantisk utväxling (lite som "async compute").
Vi har ju i flera fall snarare sett motsatsen på Nvidias GPUer, detta då Nvidias DX11 drivare faktiskt ger ett visst mått av "automatiskt" utnyttjande av flera kärnor medan motsvarande är omöjligt att erbjuda i DX12/Vulkan (där är all form av multi-core optimering explicit, d.v.s. måste utföras av spelmotorn).
Vidare är en GPU en tillståndsmaskin sett till grafik, oavsett API går det inte att komma ifrån att alla grafikkommandon måste i slutändan köras i en specifik ordning och dessa grafikkommandon måste skrivas till en enda grafikkö, så man måste serialisera accessen till grafikkö -> det ger en hård gräns för hur pass mycket de grafikintensiva delarna faktiskt kan utnyttja flera kärnor.
Om spel ska dra nytta av många kärnor måste de börja göra beräkningar som är skilda från grafik men som lämpligen körs på CPU. I det läget kvittar det totalt om man kör DX11 eller DX12!