Visa signatur
MSI Prestige 16 Ryzen 9 AI 4K OLED (tidigare Dell XPS 17, MSI GS73VR)
Byggen: White Dream (2025) - Simply Red (2015) - Liten Lian Li (2011)
MSI Prestige 16 Ryzen 9 AI 4K OLED (tidigare Dell XPS 17, MSI GS73VR)
Byggen: White Dream (2025) - Simply Red (2015) - Liten Lian Li (2011)
Cogito ergo sum ego, vos non
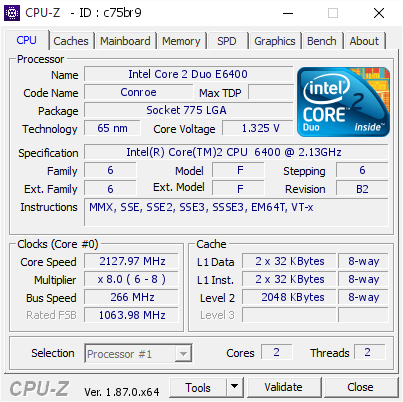
CPU: 5800x3d
GPU: 3080
RAM: 32GB
Sluta gömma din identitet, skaffa en till istället
Skrivet med hjälp av Better SweClockers
MSI Prestige 16 Ryzen 9 AI 4K OLED (tidigare Dell XPS 17, MSI GS73VR)
Byggen: White Dream (2025) - Simply Red (2015) - Liten Lian Li (2011)
MSI Prestige 16 Ryzen 9 AI 4K OLED (tidigare Dell XPS 17, MSI GS73VR)
Byggen: White Dream (2025) - Simply Red (2015) - Liten Lian Li (2011)
Copyright © 1999–2025 Geeks AB. Allt innehåll tillhör Geeks AB.
Citering är tillåten om källan anges.