

"Oh glorious cheeseburger… we bow to thee. The secrets of the universe are between the buns..."
"All my farts come straight from hell, you're already dead if you notice a smell"
TSMC kan knipa hela AMD:s processortillverkning på 7 nanometer
Visa signatur



Visa signatur
Rʏᴢᴇɴ 5800X3D / Tᴀɪᴄʜɪ X570 / 64Gʙ DDR4/ RX 6950XT Mᴇʀᴄʜ 319

Visa signatur

Visa signatur
Meshilicious, Amd 9950X3D, Asus X870E-I ,96 GB DDR5 6000,RTX5090 FE, Crucial 4TB Pcie5 m.2 / Corsiar Pcie4 4TB, Samsung 57" G9 , Samsung 49" G9 Oled

Senast redigerat
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!
Senast redigerat
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!
Visa signatur
"Oh glorious cheeseburger… we bow to thee. The secrets of the universe are between the buns..."
"All my farts come straight from hell, you're already dead if you notice a smell"
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!
Visa signatur
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!

Senast redigerat
stavning
Visa signatur
🖥️ AMD Ryzen 3700x, MSI B350 Mortar Arctic, Corsair lpx 3200, Sapphire 6900XT Nitro, Mbpro 15, MacMini.

Visa signatur
|[●▪▪●]| #Monster Battle Station(tm)#: Ryzen 3700X >-< GB-X570-AE >-< 32GB RAM >-< RTX 4070S >-< Crucial 2TB SSD |[●▪▪●]|
Visa signatur

Visa signatur
Stalin var så gammal att de fick Len´in. ;)
Visa signatur
Stalin var så gammal att de fick Len´in. ;)

Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer

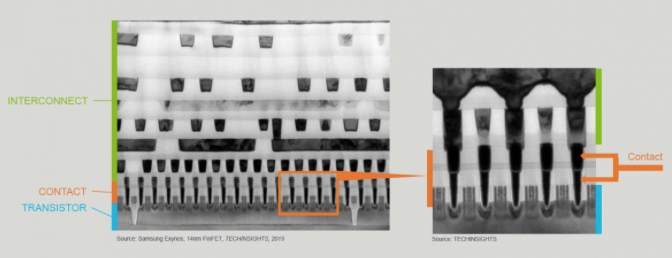
Senast redigerat
Visa signatur
"Oh glorious cheeseburger… we bow to thee. The secrets of the universe are between the buns..."
"All my farts come straight from hell, you're already dead if you notice a smell"
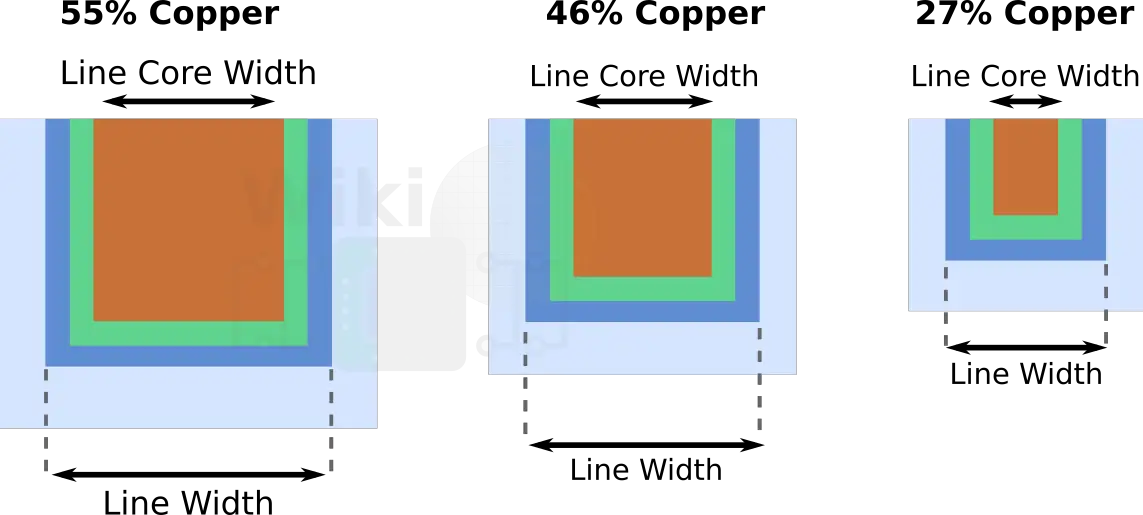
Senast redigerat
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Senast redigerat
Visa signatur
"Oh glorious cheeseburger… we bow to thee. The secrets of the universe are between the buns..."
"All my farts come straight from hell, you're already dead if you notice a smell"
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Senast redigerat
Visa signatur
Engineer who prefer thinking out of the box and isn't fishing likes, fishing likes is like fishing proudness for those without ;-)
If U don't like it, bite the dust :D
--
I can Explain it to you, but I can't Understand it for you!
Visa signatur
"Oh glorious cheeseburger… we bow to thee. The secrets of the universe are between the buns..."
"All my farts come straight from hell, you're already dead if you notice a smell"
